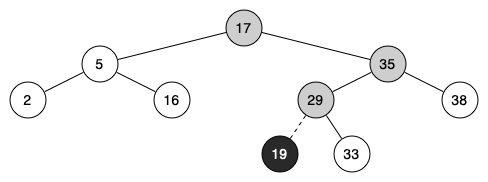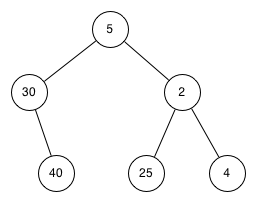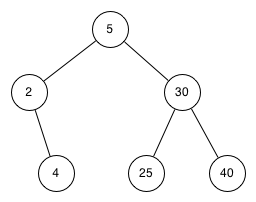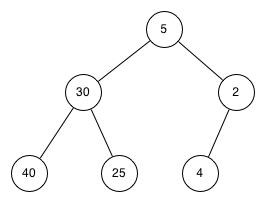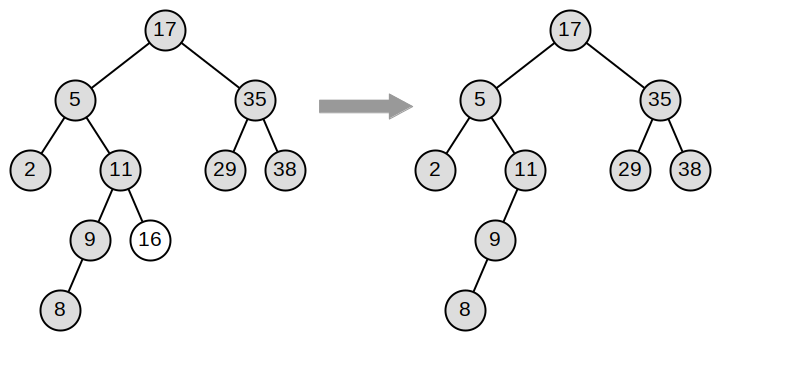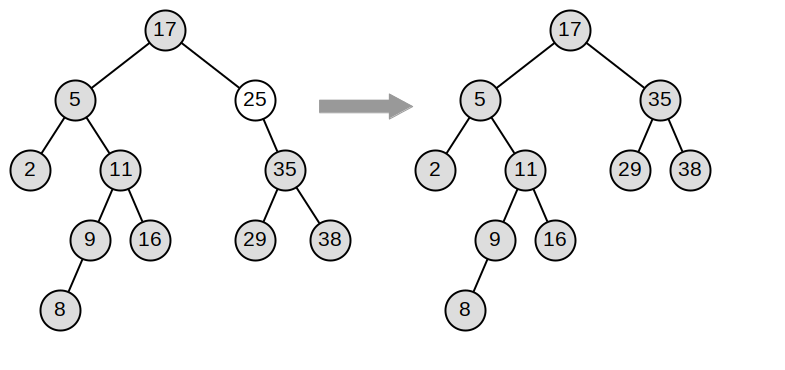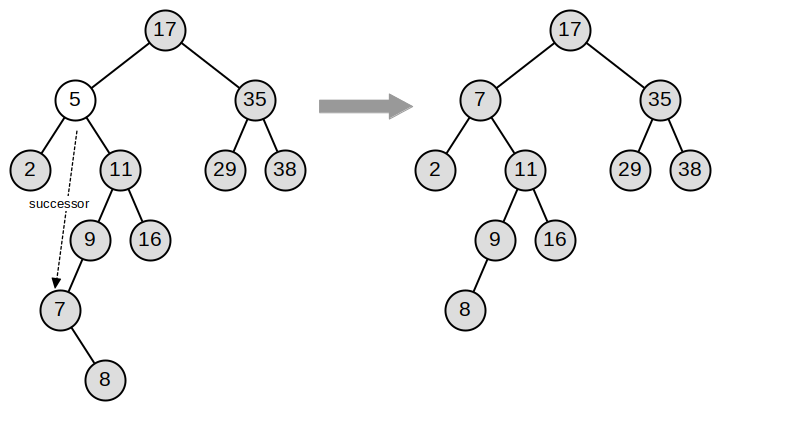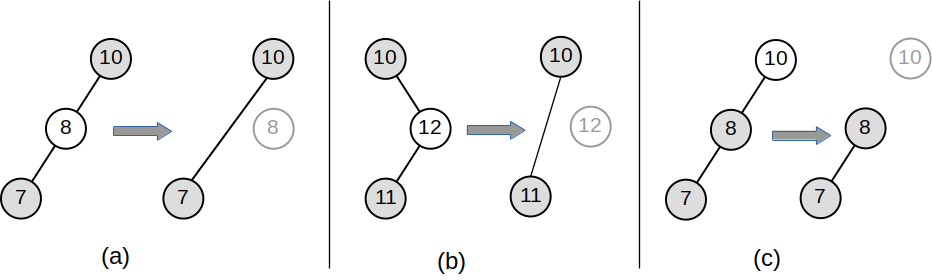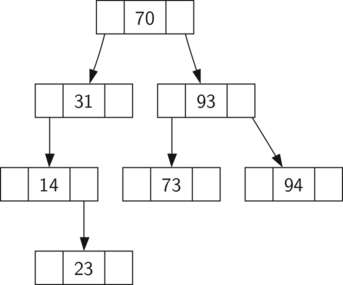
Note 6.14.3. Java Note.
There are several new Java constructs to unpack here. First, in lines 3 and 4, we define this class as requiring two generic data types,
K for the key and V for the value. We may need to do comparisons on both keys and values, so we want to make sure each data type extends Comparable.
We would also like to be able to use an extended
for loop to iterate through a BinarySearchTree, so we need to import the Iterator class in line 1. We will add the code for iteration in Subsection 6.14.5.
The
root and size properties are not declared to be either public or private. Instead, they have default access; other classes and subclasses in the same package (in this case, in the same directory as this file) can access the properties. For convenience, we will be using this default access for everything that does not need to be public.