In Chapter 2 we introduced some Big-O performance limits on Java’s ArrayLisst data type. However, we did not yet have the knowledge necessary to understand how Java implements its list data type. in Chapter 3 you learned how to implement a linked list using the nodes and references pattern. However, the nodes and references implementation still did not match the performance of the Java ArrayList. In this section we will look at the principles behind the ArrayList implementation. The idea in this section is to use Java to demonstrate the key ideas, not to replace the implementation that Java provides for us.
The key to Java’s implementation of an ArrayList is to use a data type called an array common to C, C++, Java, and many other programming languages. The array is very simple and is only capable of storing one kind of data. For example, you could have an array of integers or an array of floating point numbers, but you cannot mix the two in a single array. The array only supports two operations: indexing and assignment to an array index.
The best way to think about an array is that it is one continuous block of bytes in the computer’s memory. This block is divided up into \(n\)-byte chunks where \(n\) is based on the data type that is stored in the array. Figure 8.2.1 illustrates the idea of an array that is sized to hold six floating point values represented as double.
In Java, each floating point number uses 32 bytes of memory. So the array in Figure 8.2.1 uses a total of 192 bytes. The base address is the location in memory where the array starts. If you do code like the following:
For example, suppose that our array starts at location 0x000040, which is 64 in decimal. To calculate the location of the object at position 4 in the array we do the arithmetic: \(64 + 4 \cdot 8 = 96\text{.}\) This kind of calculation is \(O(1)\text{.}\) Of course this comes with some risks. First, since the size of an array is fixed, one cannot just add things on to the end of the array indefinitely without some serious consequences. Second, in some languages, like C, the bounds of the array are not even checked, so even though your array has only six elements in it, assigning a value to index 7 will not result in a runtime error. As you might imagine this can cause big problems that are hard to track down. In the Linux operating system, accessing a value that is beyond the boundaries of an array will often produce the rather uninformative error message “segmentation violation.”
Let’s look at how the strategy outlined above works for a very simple implementation. To begin, we will only implement the constructor, a private resize method, and the append method. We will call this class MiniArrayList. In the constructor, we will need to initialize two instance variables. The first will keep track of the size of the current array; we will call this maxSize. The second instance variable will keep track of the current end of the list; we will call this one lastIndex. Listing Listing 8.2.3 contains the code for the first few methods of MiniArrayList. The default constructor method initializes the two instance variables and then creates a default-length element array called array. It calls the one-parameter constructor that takes the number of elements we want in the initial list.
We cannot create a generic array in line 15, so we create an array of Object, which is the superclass of all object types. This allows us to assign a value of any object type to an Object variable (because of polymorphism).
public class MiniArrayList<T> {
static final int DEFAULT_SIZE = 16;
private int maxSize;
private int lastIndex;
private Object[] array;
public MiniArrayList() {
this(DEFAULT_SIZE);
}
public MiniArrayList(int startSize) {
this.maxSize = startSize;
this.lastIndex = 0;
this.array = new Object[startSize];
}
public void append(T value) {
if (this.lastIndex > this.maxSize - 1) {
this.resize();
}
this.array[this.lastIndex] = value;
this.lastIndex++;
}
private void resize() {
int newSize = (this.maxSize < DEFAULT_SIZE) ?
DEFAULT_SIZE : this.maxSize * 2;
System.out.println("Resize to " + newSize);
Object[] newArray = new Object[newSize];
for (int i = 0; i < maxSize; i++) {
newArray[i] = this.array[i];
}
this.maxSize = newSize;
this.array = newArray;
}
public String toString() {
String result = "[";
for (int i = 0; i < this.lastIndex; i++) {
result = result + this.array[i].toString();
if (i != this.lastIndex - 1) {
result = result + ", ";
}
}
result += "]";
return result;
}
public int size() {
return this.lastIndex;
}
}
We have also implemented the toString and size methods for convenience; these will help us print out the current information about a MiniArrayList while debugging. Similarly, we have included debugging output in line 29 to check that resizing occurs at the proper time.
Next, we implement the append method. The first thing append does is test for the condition where lastIndex is greater than the number of available index positions in the array. If this is the case then resize is called. Once the array is resized the new value is added to the list at lastIndex, and lastIndex is incremented by one.
The resize method calculates a new size for the array by doubling the capacity each time the array is resized. (If the original size is less than 16, we resize to 16.) There are many methods that could be used for resizing the array. Some implementations double the size of the array every time as we do here, some use a multiplier of 1.5, and some use powers of two. Python uses a multiplier of 1.125 plus a constant. Doubling the array size leads to a bit more wasted space at any one time, but is much easier to analyze.
Once a new array has been allocated, the values from the old list must be copied into the new array; this is done in the loop starting in line 31. Finally, the values maxSize and lastIndex must be updated, newArray is saved as this.array. In a language like C, the old block of memory referenced by this.array would have to be explicitly returned to the system for reuse. However, recall that in Java, objects that are no longer referenced are automatically cleaned up by the garbage collection algorithm.
Before we move on, let’s analyze why this strategy gives us an average \(O(1)\) performance for append. The key is to notice that most of the time the cost to append an item \(c_i\) is 1. The only time that the operation is more expensive is when last_index is a power of 2. When lastIndex is a power of 2 then the cost to append an item is \(O(lastIndex)\text{.}\) We can summarize the cost to insert the \(i_{th}\) item as follows:
\begin{equation*}
c_i =
\begin{cases}
O(lastIndex) \text{ if } i \text{ is a power of 2} \\
O(1) \text{ otherwise}
\end{cases}
\end{equation*}
Since the expensive cost of copying lastIndex items occurs relatively infrequently, we spread the cost out, or amortize, the cost of insertion over all of the appends. When we do this the cost of any one insertion averages out to \(O(1)\text{.}\) For example, consider the case where you have already appended 16 items. Each of these 16 appends costs you just one operation to store in the array that was already allocated to hold 16 items. When the 17th item is added, a new array of size 32 is allocated and the 16 old items are copied. But now you have room in the array for 16 additional low cost appends. Mathematically we can show this as follows:
\begin{equation*}
\begin{aligned}
cost_{total} &= n + \sum_{j=0}^{\log_2{n}}{2^j} \\
&= n + 2n \\
&= 3n \\
\end{aligned}
\end{equation*}
The summation in the previous equation may not be obvious to you, so let’s think about that a bit more. The sum goes from zero to \(\log_2{n}\text{.}\) The upper bound on the summation tells us how many times we need to double the size of the array. The term \(2^j\) accounts for the copies that we need to do when the array is doubled. Since the total cost to append n items is \(3n\text{,}\) the cost for a single item is \(3n/n = 3\text{.}\) Because the cost is a constant we say that it is \(O(1)\text{.}\) This kind of analysis is called amortized analysis and is very useful in analyzing more advanced algorithms.
Next, let us turn to the index operators. Listing Listing 8.2.4 shows our Java implementation for index and assignment to an array location. Recall that we discussed above that the calculation required to find the memory location of the \(i_{th}\) item in an array is an \(O(1)\) arithmetic expression. Even languages like C hide that calculation behind a nice array index operator, so in this case the C and the Java code look very much the same. In fact, in Java it is essentially impossible to get the actual memory location of an object for use in a calculation like this, so we will just rely on the array’s built-in index operator.
@SuppressWarnings("unchecked")
public T getItem(int index) {
if (index >= 0 && index < this.lastIndex) {
return (T) array[index];
} else {
throw new IndexOutOfBoundsException(index);
}
}
public void setItem(int index, T value) {
if (index >= 0 && index < this.lastIndex) {
array[index] = value;
} else {
throw new IndexOutOfBoundsException(index);
}
}
Note8.2.5.Java Notes.
When we cast the value from the array (which is an Object) to our generic type in line 4, it is possible that the cast is illegal. The compiler gives us a warning about this. However, we know that we are restricted to our generic type T, so the warning is not useful. That is why line 1 suppresses this warning that requires us to check for a valid cast.
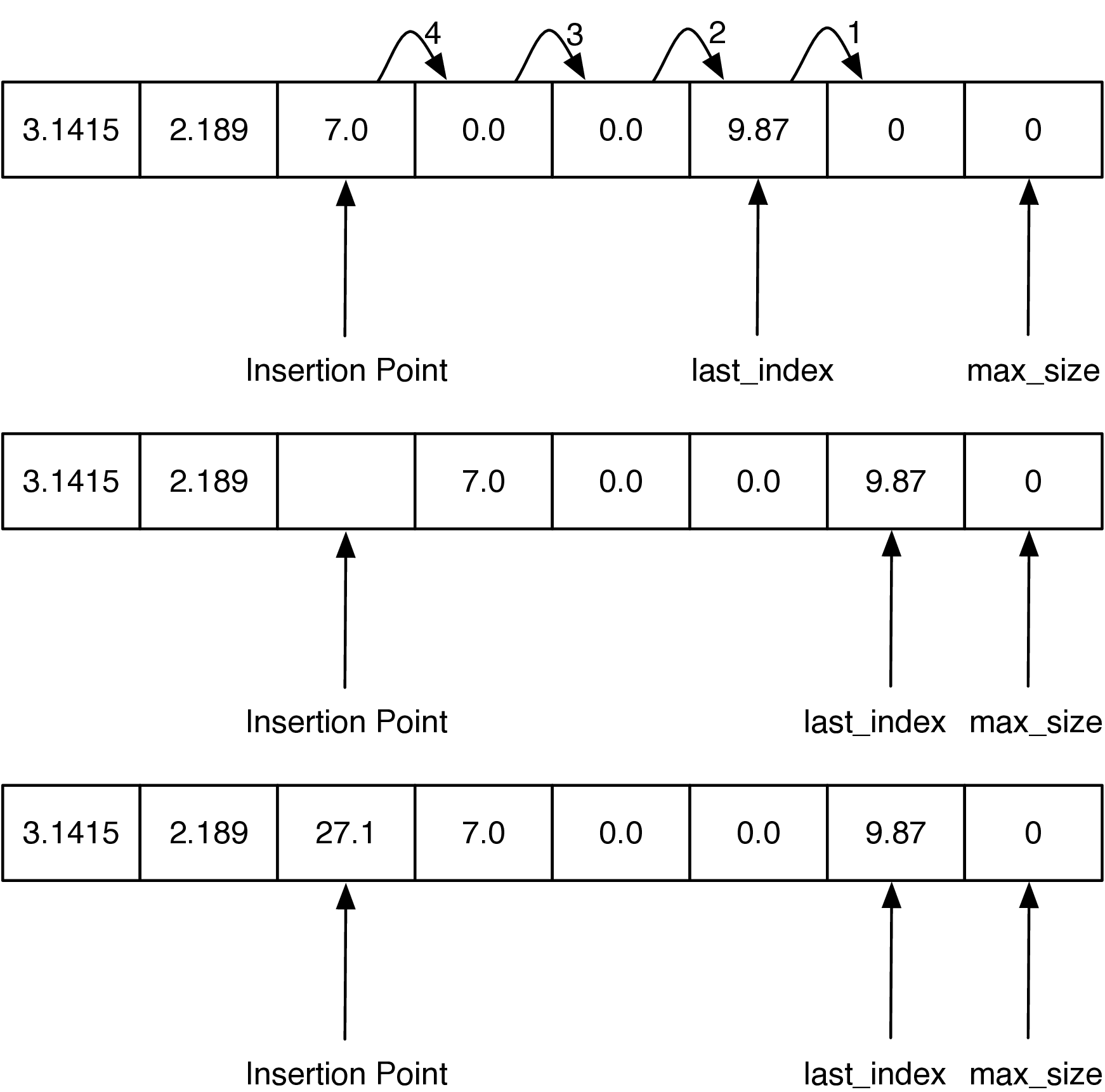
Finally, let’s take a look at one of the more expensive list operations: insertion. When we insert an item into an ArrayList we will need to first shift everything in the list at the insertion point and beyond ahead by one index position in order to make room for the item we are inserting. The process is illustrated in Figure 8.2.6.
The key to implementing insert correctly is to realize that as you are shifting values in the array you do not want to overwrite any important data. The way to do this is to work from the end of the list back toward the insertion point, copying data forward. Our implementation of insert is shown in Listing 8.2.7. Note how the loop decrements the index to ensure that we are copying existing data into the unused part of the array first, and then subsequent values are copied over old values that have already been shifted. If the loop had started at the insertion point and copied that value to the next larger index position in the array, the old value would have been lost forever.
public void insert(int index, T value) {
if (index <= 0 && index <= this.lastIndex) {
if (this.lastIndex > this.maxSize - 1) {
this.resize();
}
for (int i = this.lastIndex; i > index - 1; i--) {
this.array[i + 1] = this.array[i];
}
this.lastIndex++;
this.array[index] = value;
} else {
throw new IndexOutOfBoundsException(index);
}
}
The performance of the insert is \(O(n)\text{,}\) since in the worst case we want to insert something at index 0, and we have to shift the entire array forward by one. On average we will only need to shift half of the array, but this is still \(O(n)\text{.}\) You may want to go back to Chapter 3 and remind yourself how all of these list operations are done using nodes and references. Neither implementation is right or wrong; they just have different performance guarantees that may be better or worse depending on the kind of application you are writing. In particular, do you intend to add items to the beginning of the list most often, or does your application add items to the end of the list? Will you be deleting items from the list or only adding new items to the list?
There are several other interesting operations that we have not yet implemented for our ArrayList including: pop, del, index, and making the ArrayList iterable. We leave these enhancements to the ArrayList as an exercise for you.