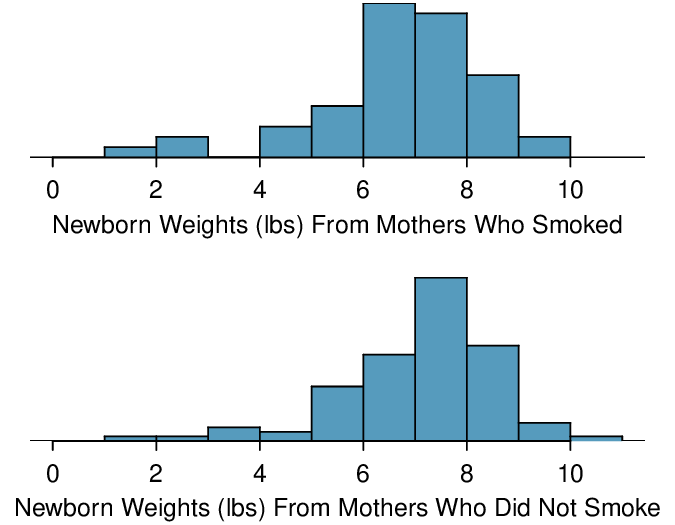
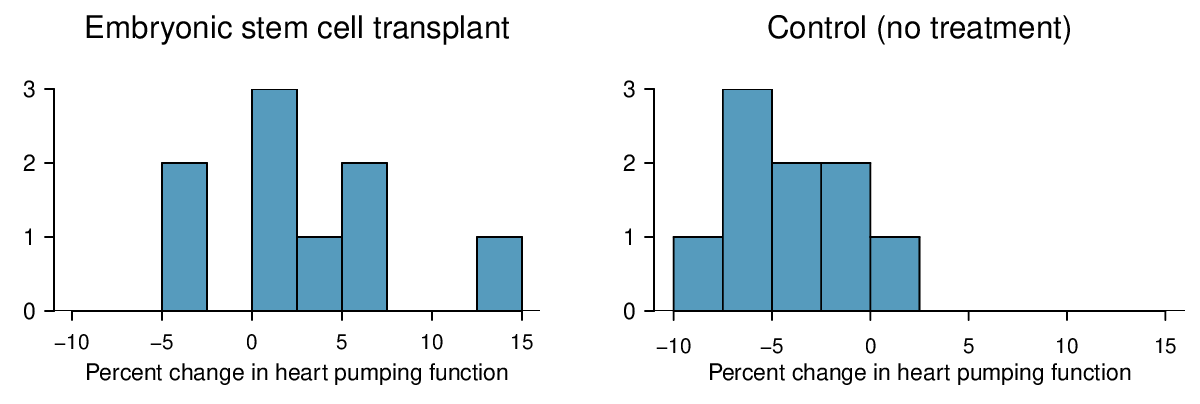
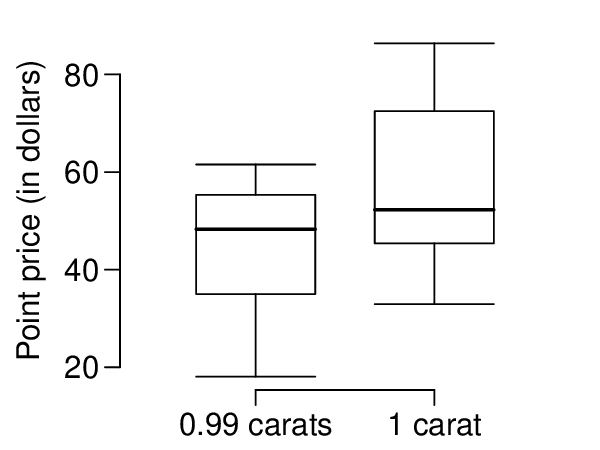
Identify: The parameter we want to estimate is
\(\mu_{1}-\mu_2\text{,}\) which is the true average score under Version A
\(-\) the true average score under Version B. We will estimate this parameter at the 95% confidence level.
Choose: Because we are comparing two means, we will use a 2-sample
\(t\)-interval.
Check: The data was collected from a randomized experiment with two treatments: Version A and Version B of test. The 10% condition does not need to be checked here since we are not sampling from a population. There were 30 students in each group, so the condition that both group sizes are at least 30 is met.
Calculate: We will calculate the confidence interval as follows.
\begin{gather*}
\text{ point estimate } \ \pm\ t^{\star} \times SE\ \text{ of estimate }
\end{gather*}
The point estimate is the difference of sample means:
\begin{gather*}
\bar{x}_1-\bar{x}_2 = 79.4 - 74.1 = 5.3
\end{gather*}
The \(SE\) of a difference of sample means is:
\begin{gather*}
\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}} = \sqrt{\frac{14^2}{30} + \frac{20^2}{30}} = 4.46
\end{gather*}
In order to find the critical value
\(t^{\star}\text{,}\) we must first find the degrees of freedom. Using a calculator, we find
\(df=51.9\text{.}\) We round down to 50, and using a
\(t\)-table at row
\(df = 50\) and confidence level 95%, we get
\(t^{\star} = 2.009\text{.}\)
The 95% confidence interval is given by:
\begin{align*}
(79.4 - 74.1) \ \pm\ \amp 2.009\times \sqrt{\frac{14^2}{30} + \frac{20^2}{30}} \qquad df = 45.97\\
5.3 \ \pm\ \amp 2.009\times 4.46\\
\amp =(-3.66, 14.26)
\end{align*}
Conclude: We are 95% confident that the true difference in average score between Version A and Version B is between -2.5 and 13.1 points. Because the interval contains both positive and negative values, the data do not convincingly show that one exam version is more difficult than the other, and the teacher should not be convinced that she should add points to the Version B exam scores.