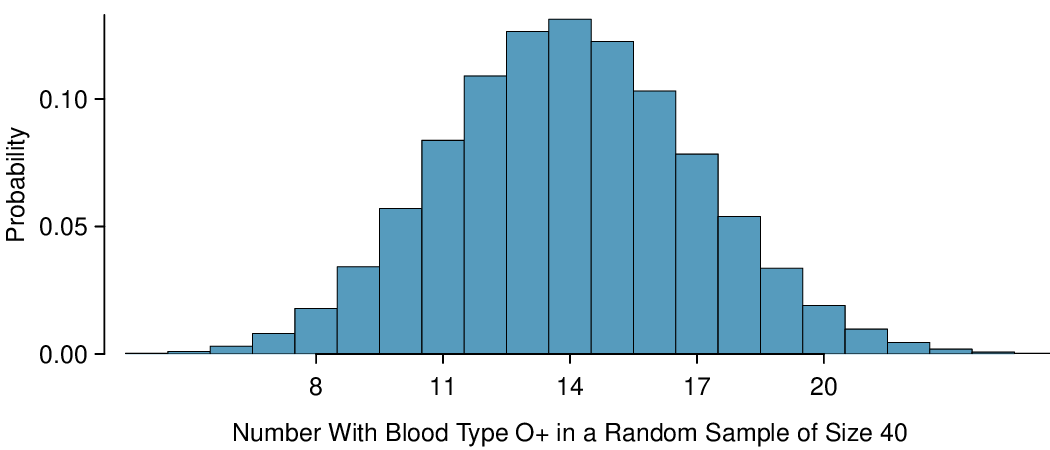
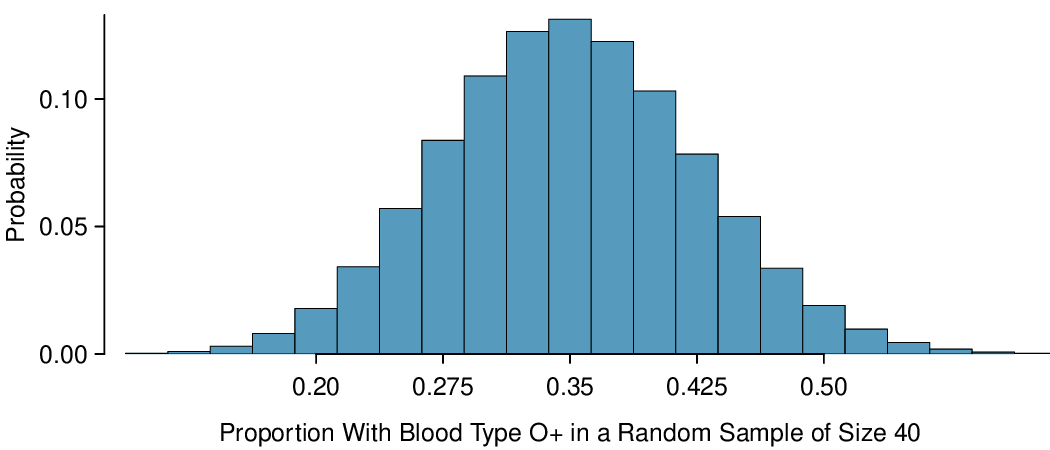
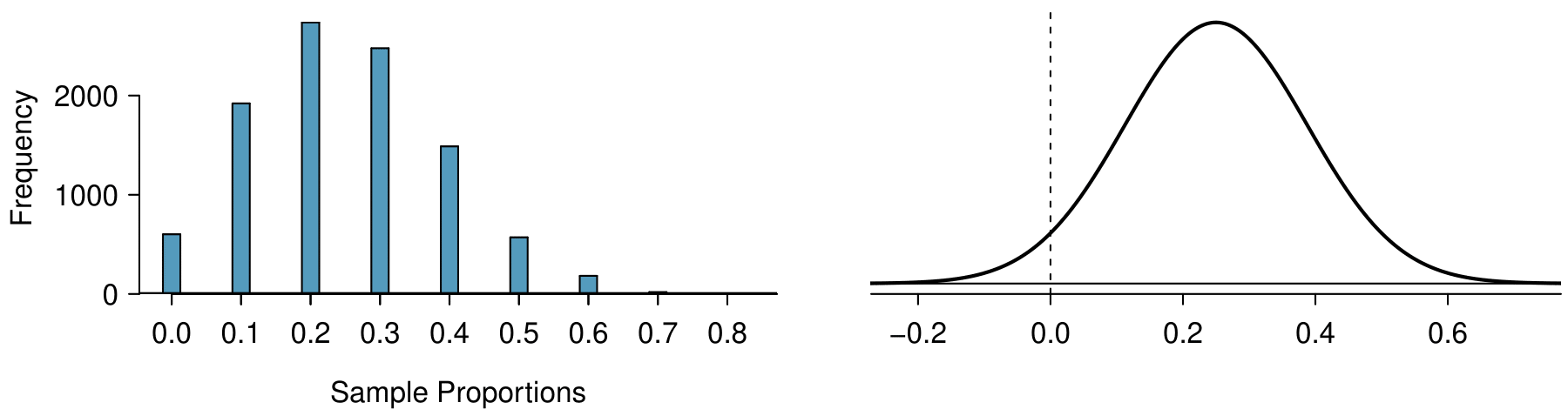
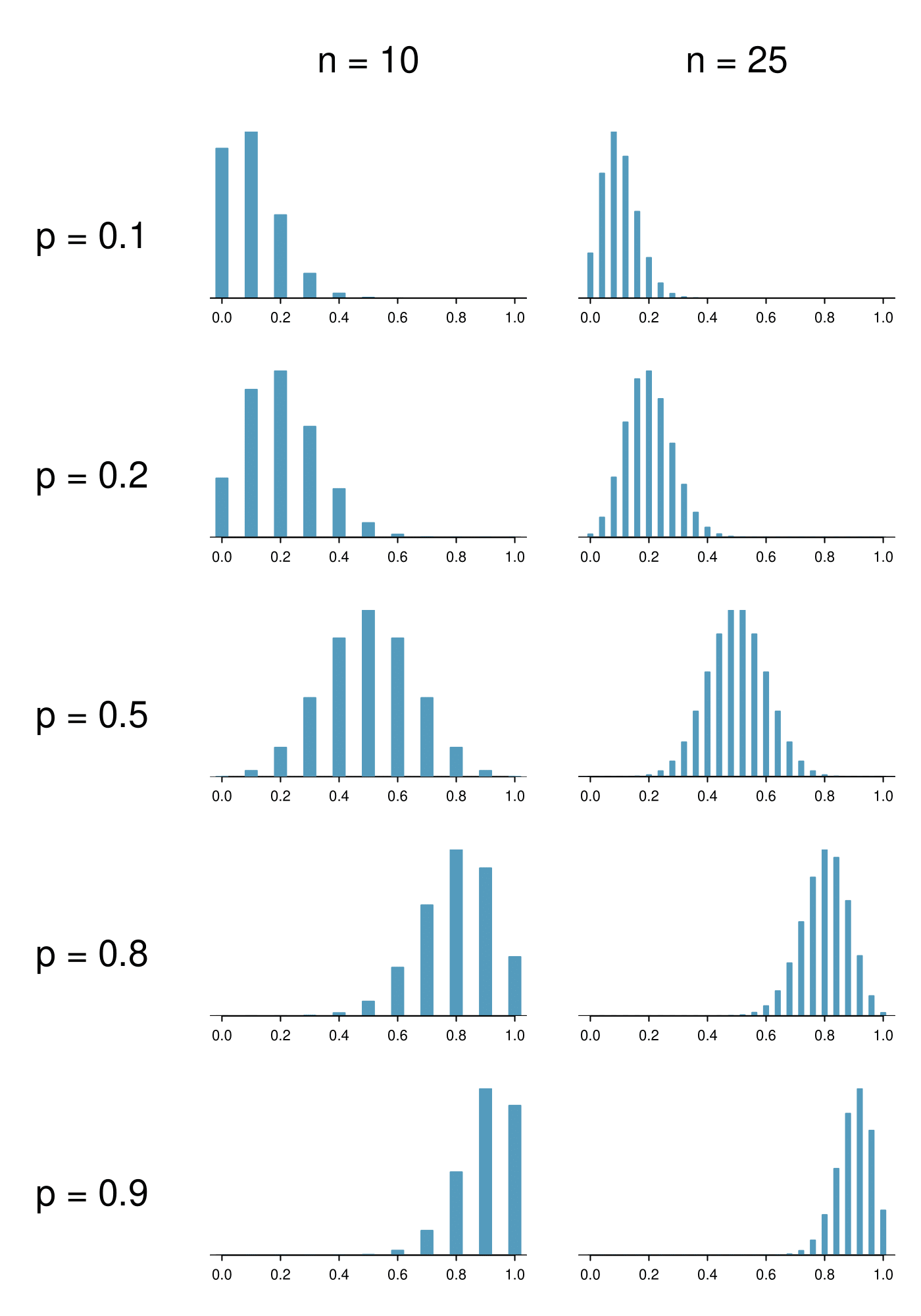
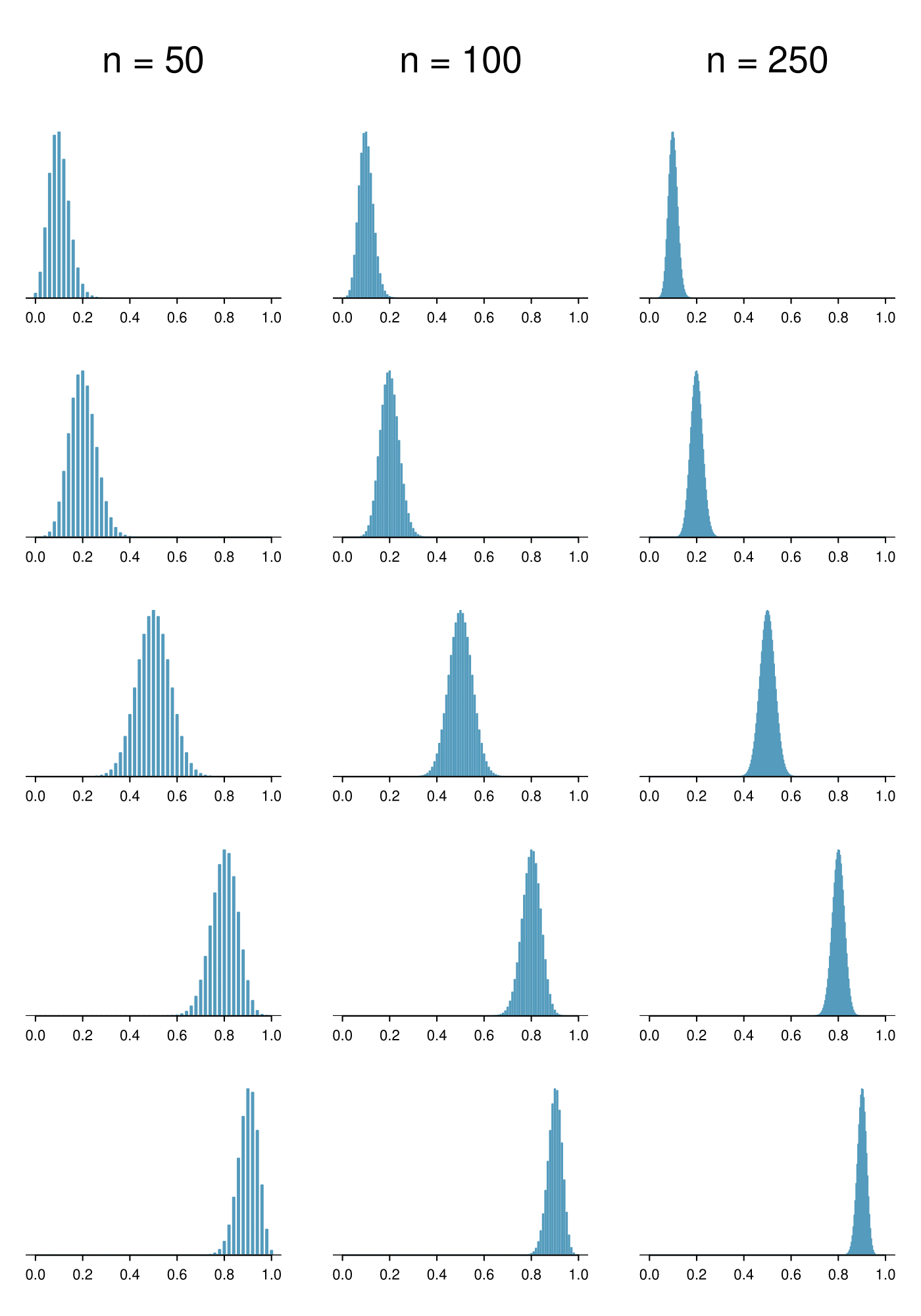
The mean of the sample proportion is the population proportion: 0.35. That is, if we took many, many samples and calculated
\(\hat{p}\text{,}\) these values would average out to
\(p = 0.35\text{.}\)
The standard deviation of \(\hat{p}\) is described by the standard deviation for the proportion:
\begin{gather*}
\sigma_{\hat{p}} = \sqrt{\frac{p(1-p)}{n}} = \sqrt{\frac{0.35(0.65)}{400}} = 0.024
\end{gather*}
The sample proportion will typically be about 0.024 or 2.4% away from the true proportion of
\(p = 0.35\text{.}\) We’ll become more rigorous about quantifying how close
\(\hat{p}\) will tend to be to
\(p\) in
Chapter 5.