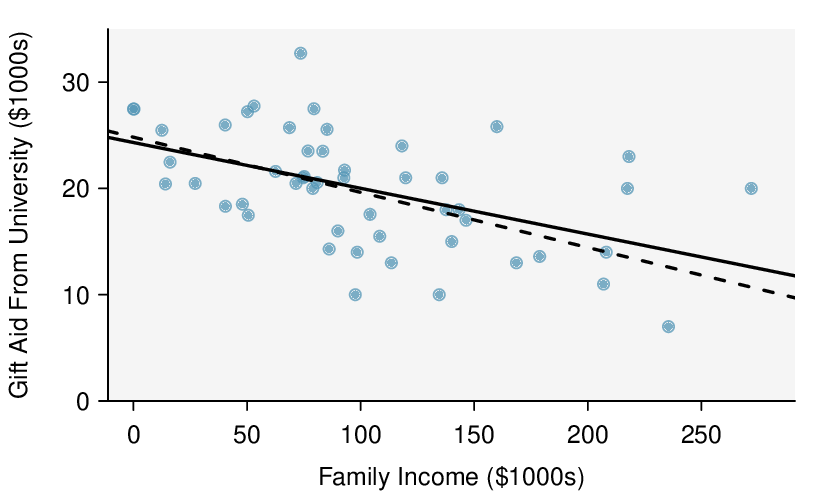
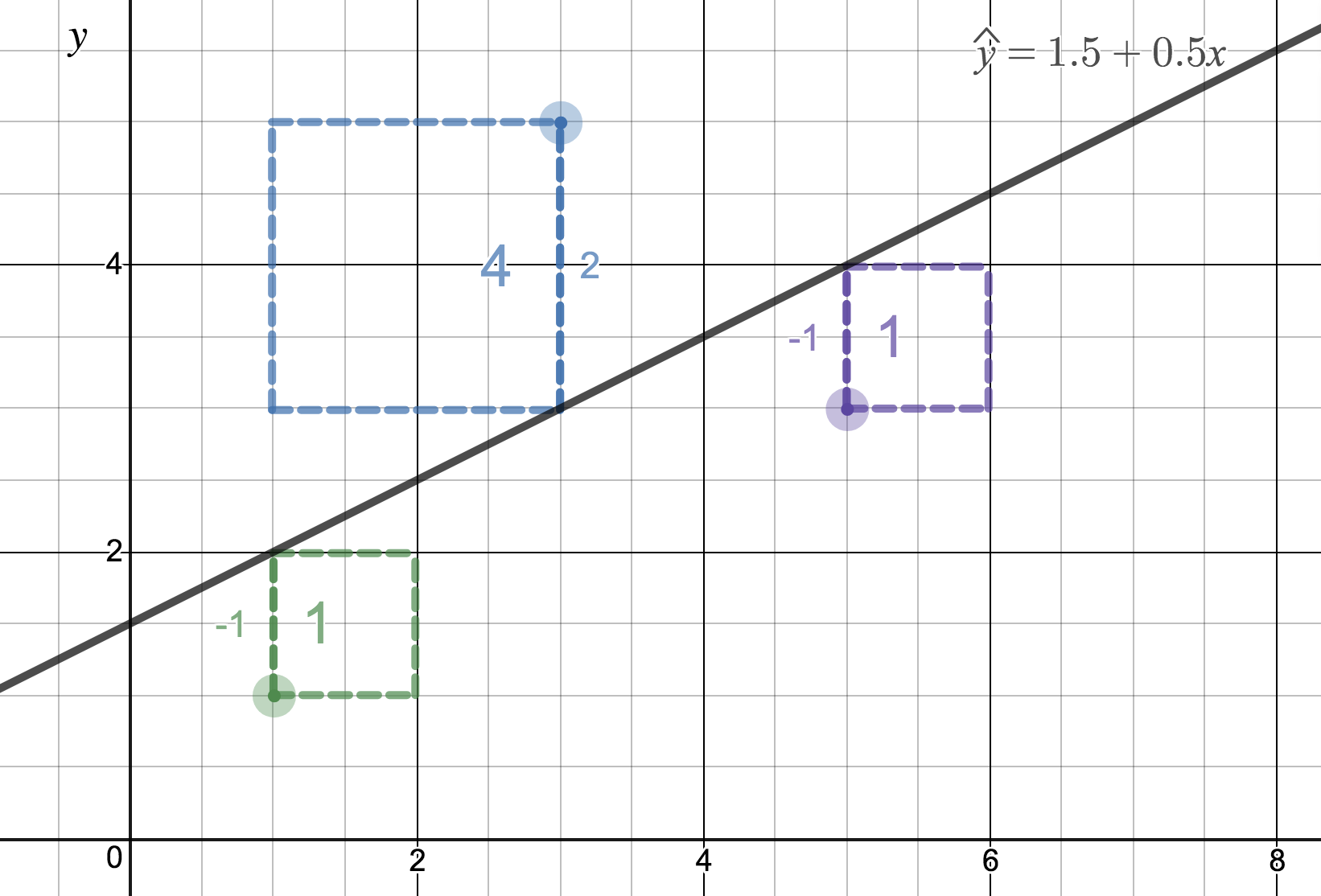
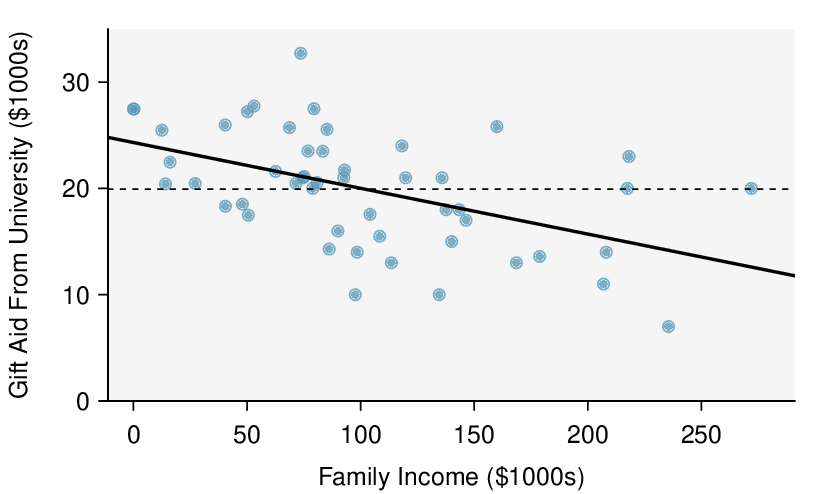
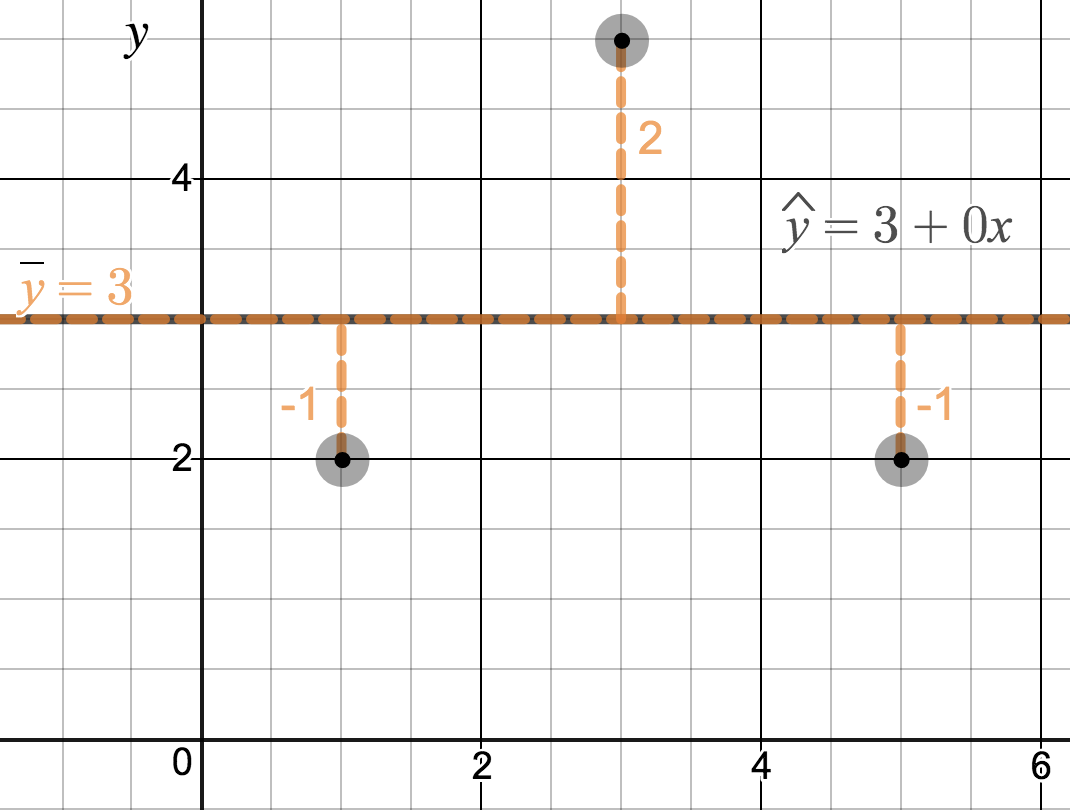
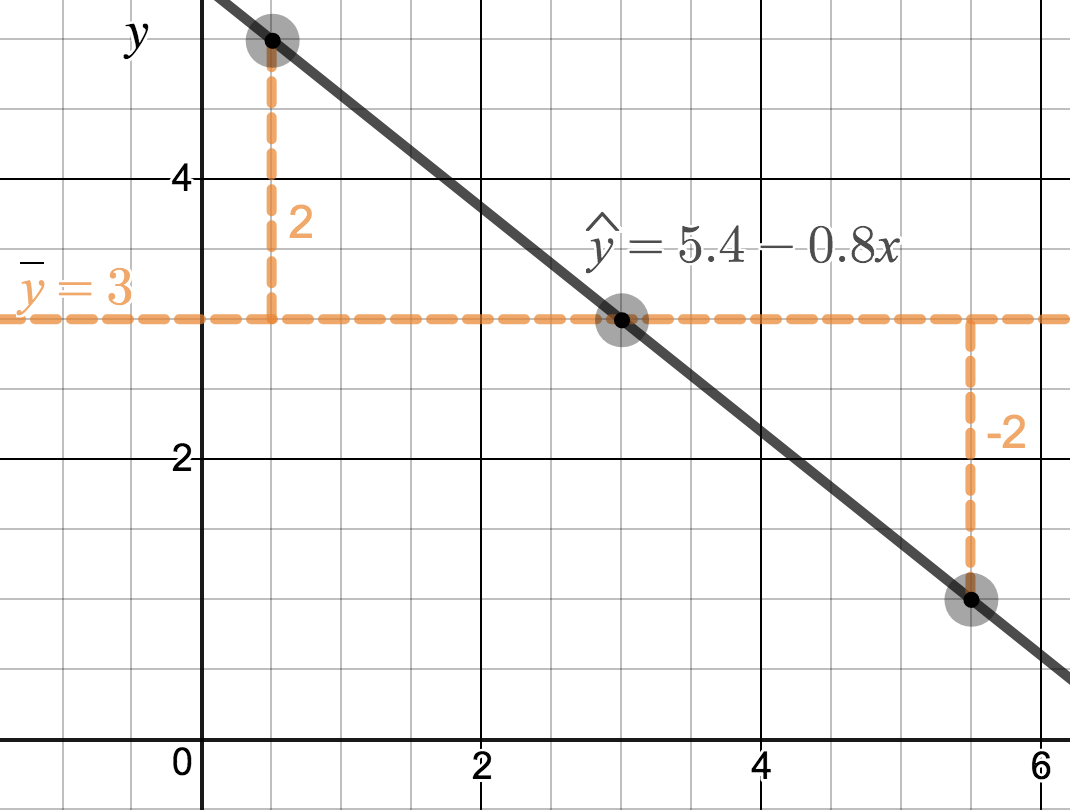
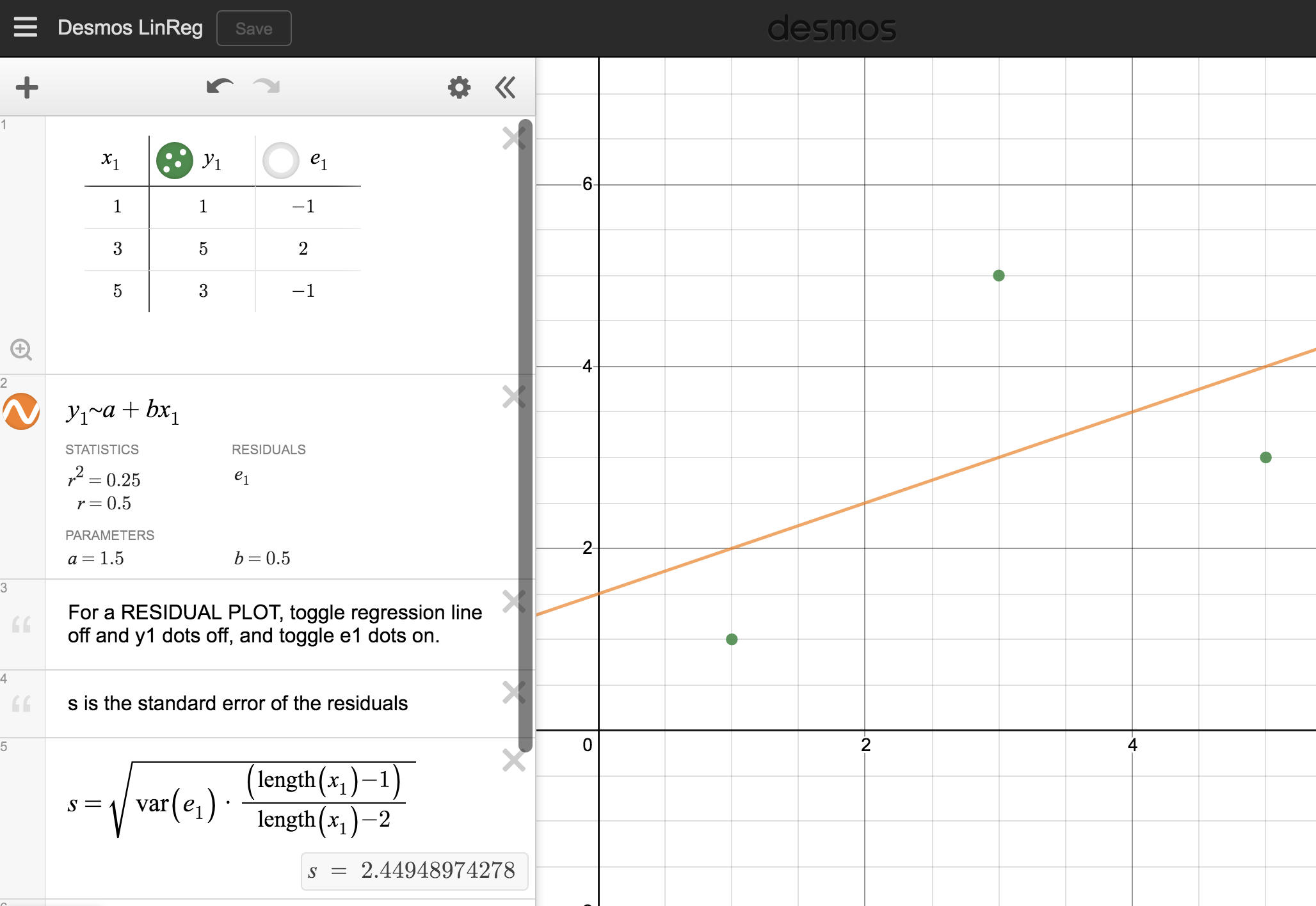
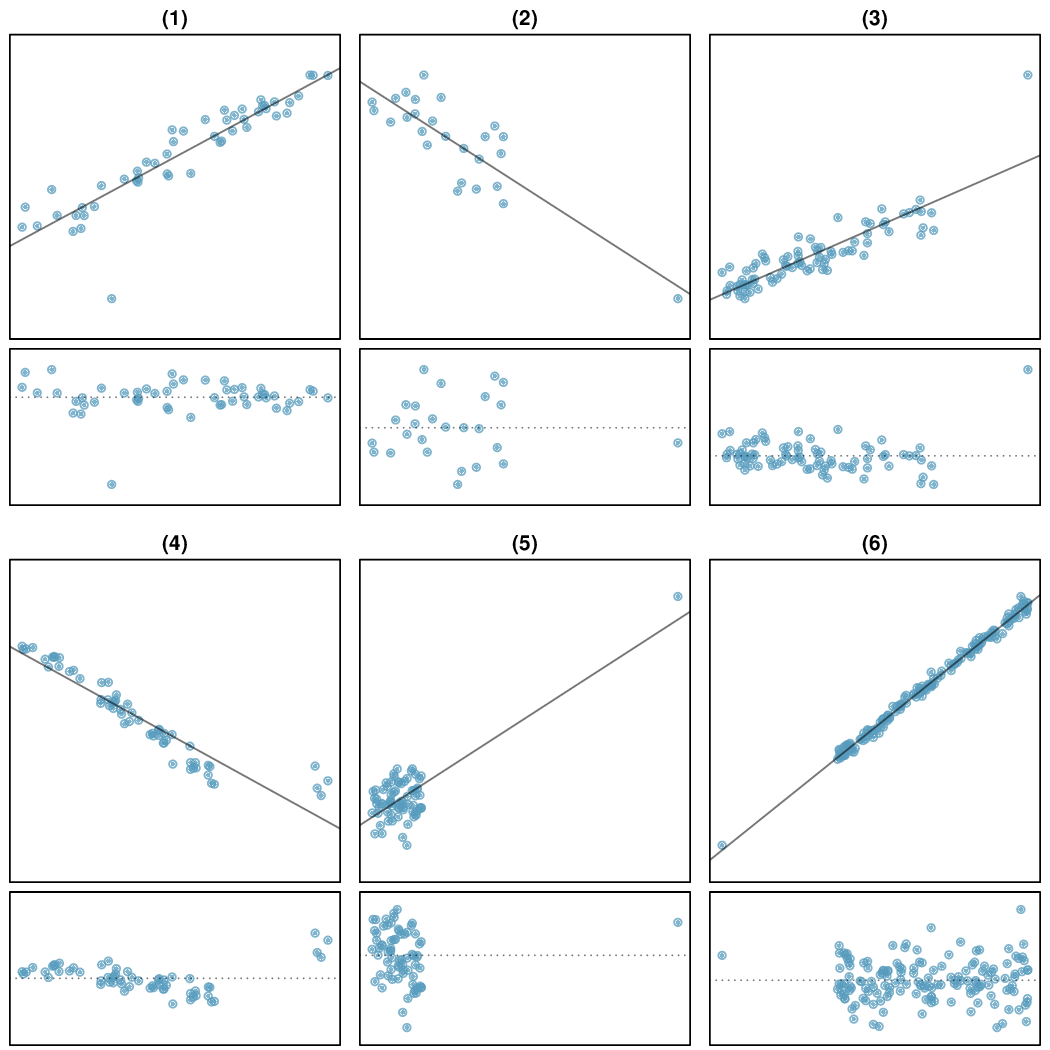
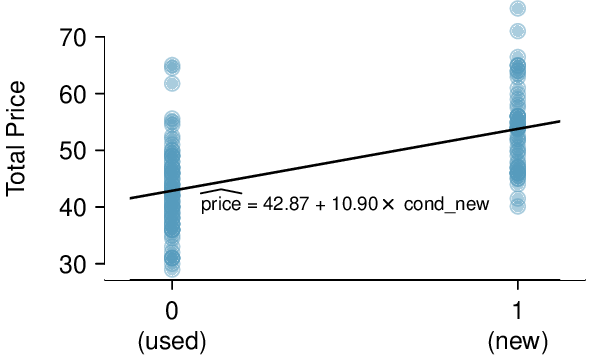
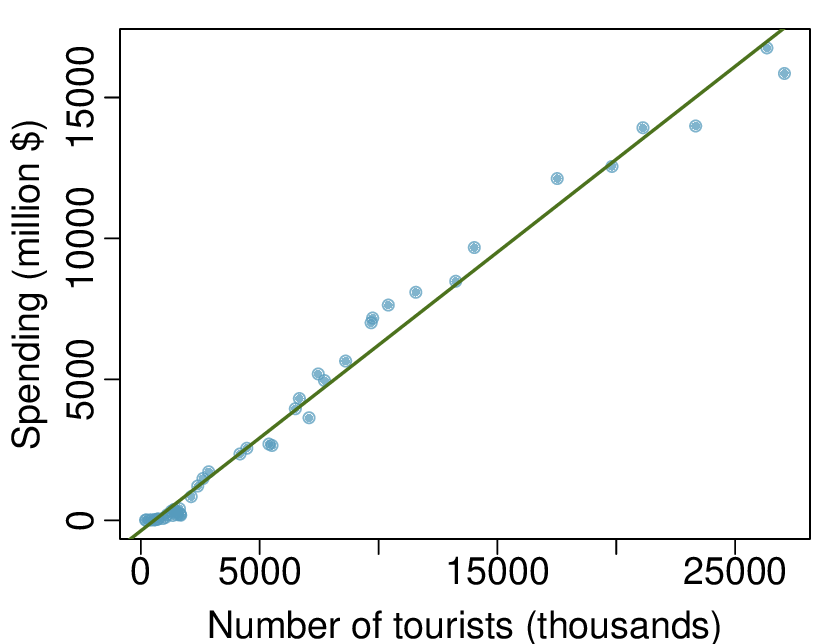
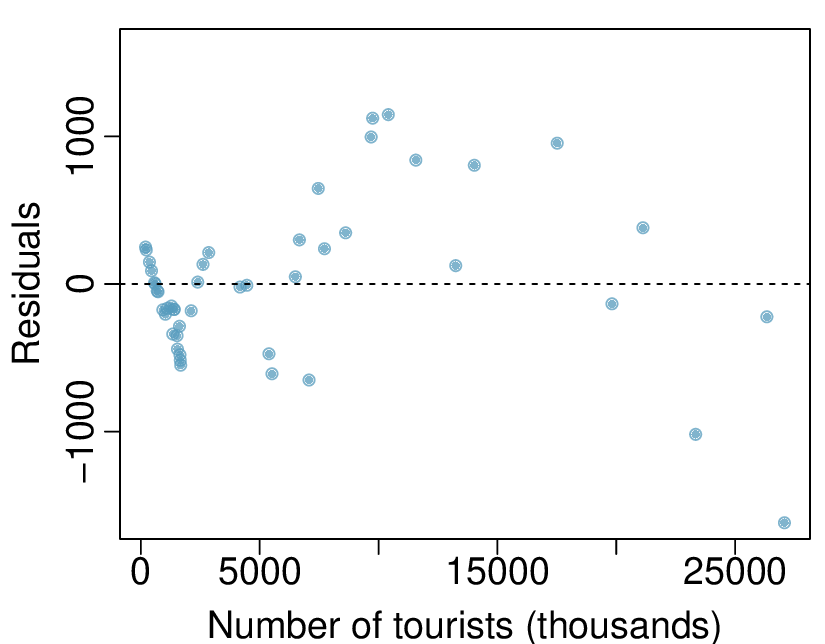
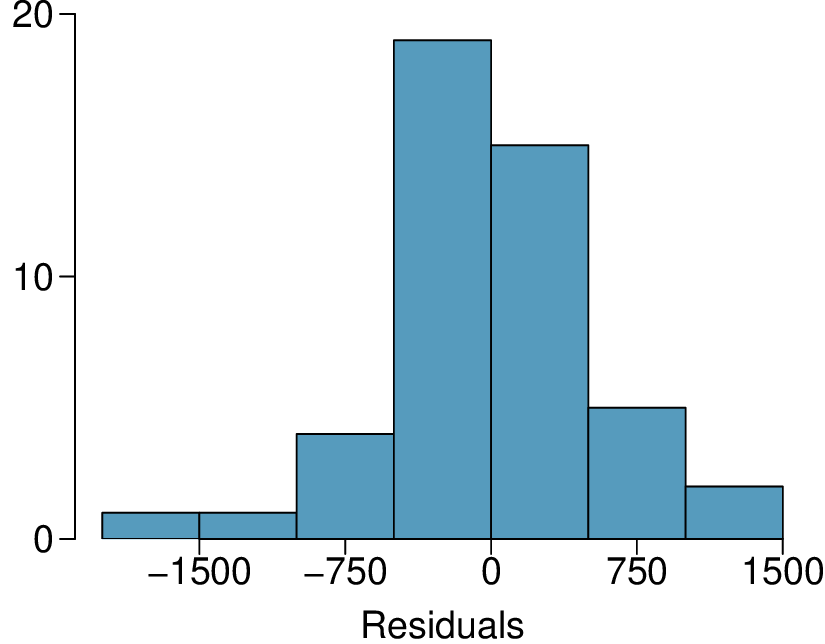
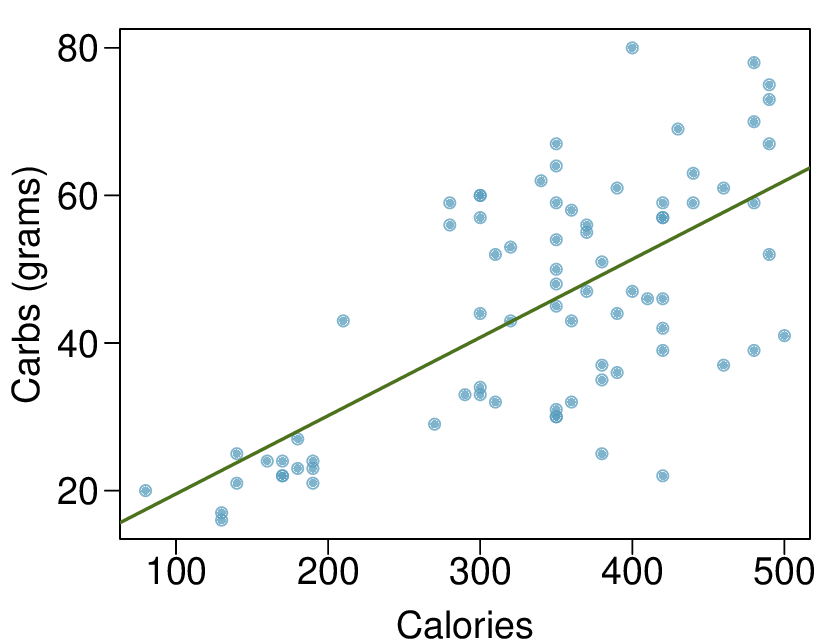
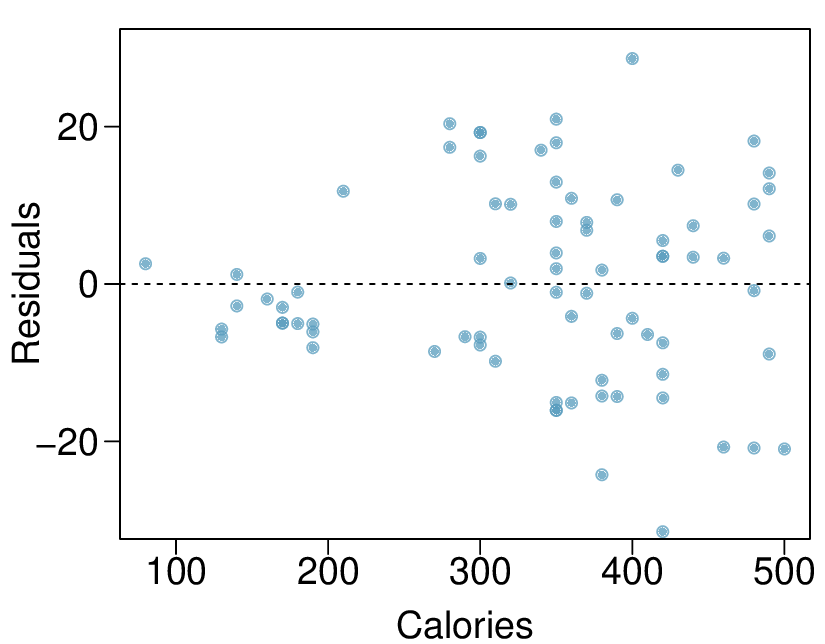
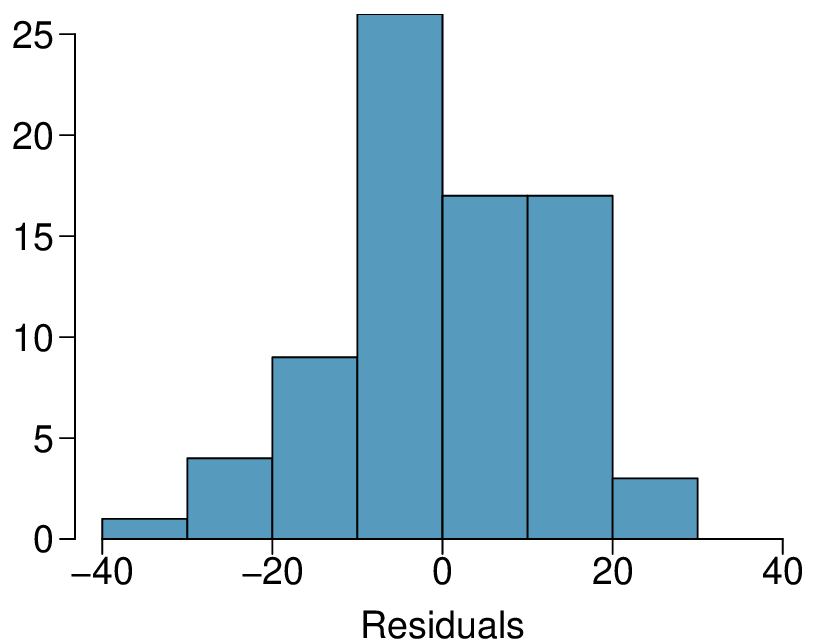
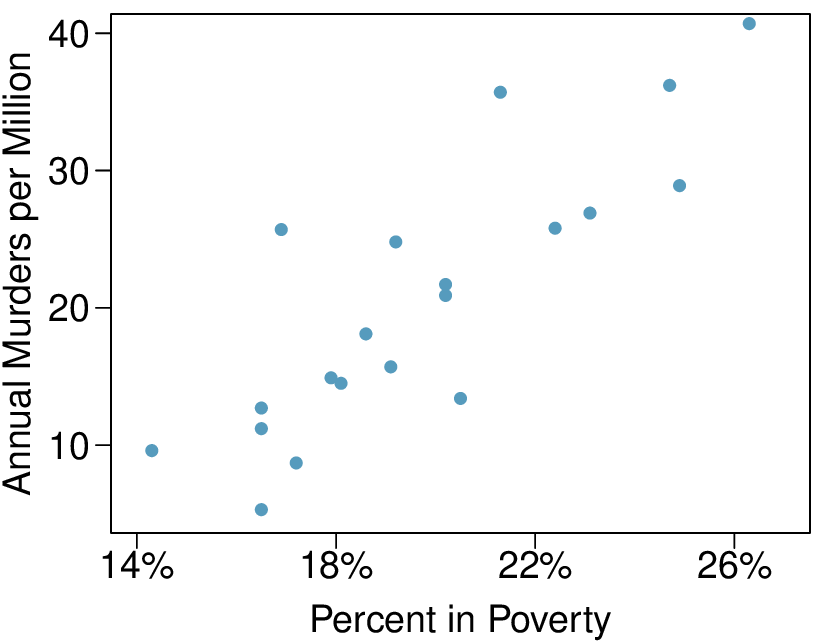
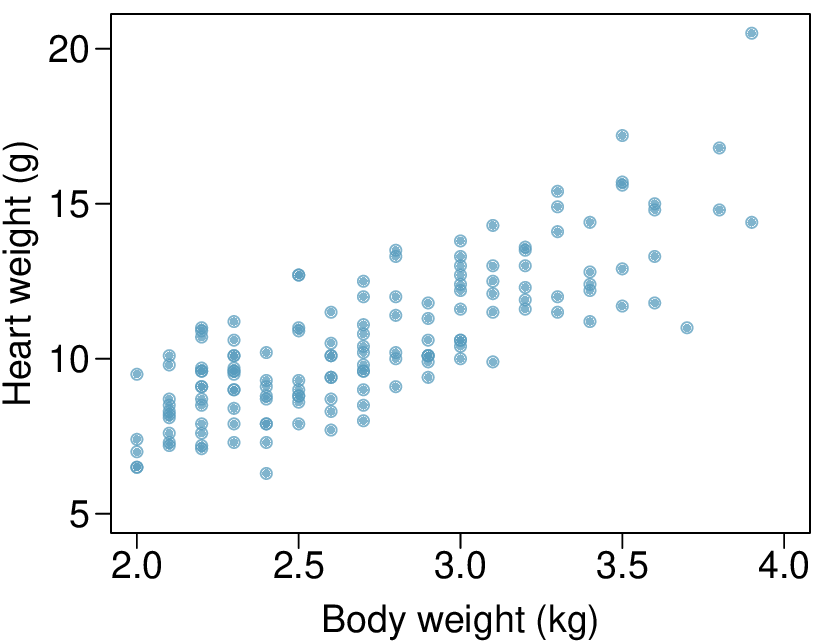
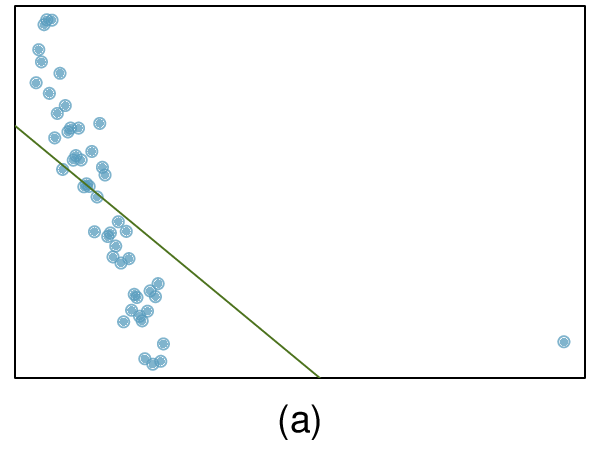
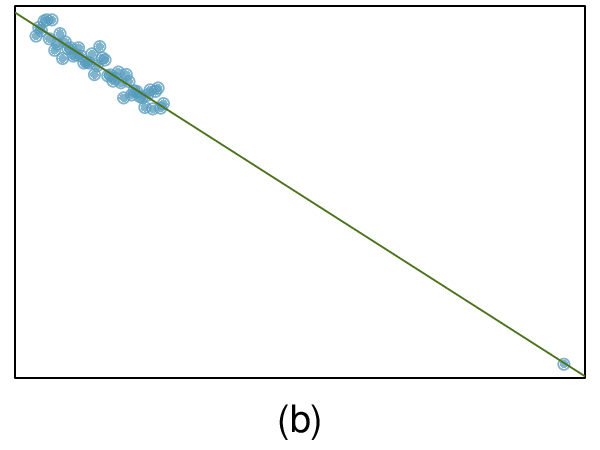
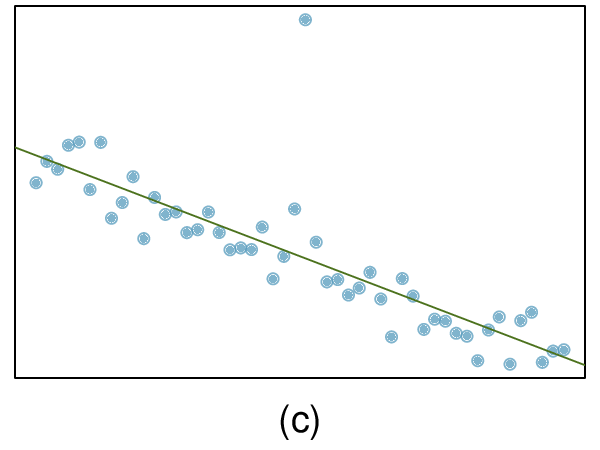
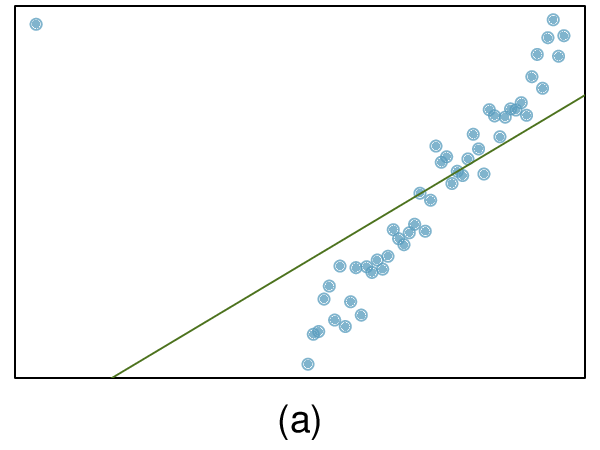
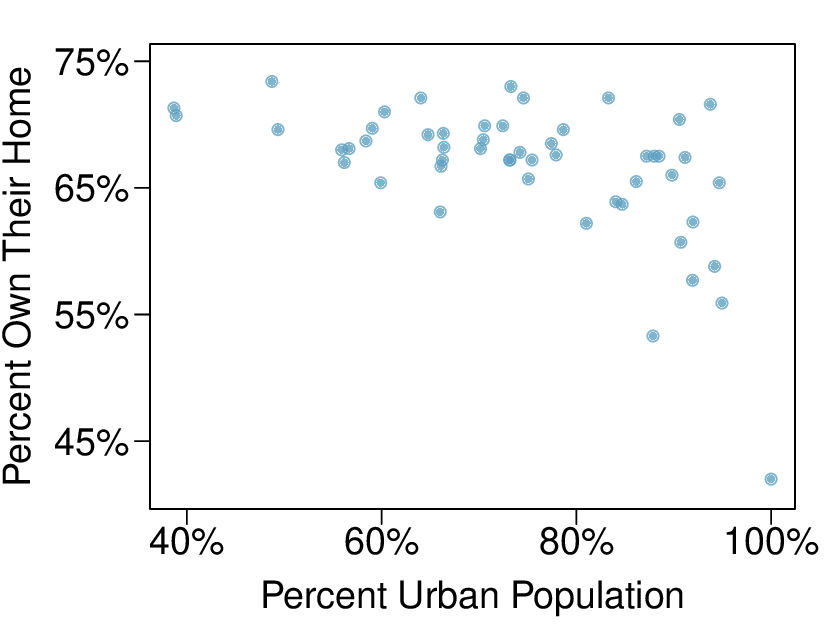
We’ll look at the second row, which corresponds to the slope. The first column, Estimate = -0.0431, tells us our best estimate for the slope of the population regression line. We call this point estimate
\(b\text{.}\) The second column, Std. Error = 0.0108, is the standard error of this point estimate. The third column, t value = -3.98, is the
\(T\) test statistic for the null hypothesis that the slope of the population regression line = 0. The last column, Pr
\((>|t|) = 0.0002\text{,}\) is the p-value for this two-sided
\(T\)-test. We will get into more of these details in
Section 8.4.