
Section 0.6 Programming Languages
Most computer programs today are written in a high-level language , such as Java, Python, C, C++, or FORTRAN.
A programming language is considered high level if its statements resemble English-language statements. For example, all of the languages just mentioned have some form of an “if” statement, which says, “if some condition holds, then take some action.”
Computer scientists have invented hundreds of high-level programming languages, although relatively few of these have been put to practical use.
Some of the widely used languages have special features that make them suitable for one type of programming application or another. COBOL (COmmon Business-Oriented Language), for example, is still used in commercial applications. FORTRAN (FORmula TRANslator) is still preferred by some engineers and scientists. C and C++ are still the primary languages used by operating system programmers.
In addition to having features that make them suitable for certain types of applications, high-level languages use symbols and notation that make them easily readable by humans. For example, arithmetic operations in Java make use of familiar operators such as “\(+\)” and “\(-\)” and “/”, so that arithmetic expressions look more or less the way they do in algebra. So, to take the average of two numbers, you might use the expression
(a + b) / 2 Subsection 0.6.1 Machine Languages
The problem is that computers cannot directly understand high-level languages.. In order for a computer to run a program, it must first be translated into the computer’s machine language , which is the language understood by its CPU or microprocessor.
Each type of microprocessor has its own particular machine language. That’s why when you buy software it typically runs on either a Macintosh or on a Windows machine, but not on both. If a program can run on just one type of chip, it is known as platform dependent .
In general, machine languages are based on the binary code, a two-valued system that is well suited for electronic devices. In a binary representation scheme, everything is represented as a sequence of 1’s and 0’s, which corresponds closely to the computer’s electronic “on” and “off” states.
For example, in binary code, the number 13 would be represented as 1101. Similarly, a particular address in the computer’s memory might be represented as 01100011, and an instruction in the computer’s instruction set might be represented as 001100.
The instructions that make up a computer’s machine language are very simple and basic. For example, a typical machine language might include instructions for ADD, SUBTRACT, DIVIDE, and MULTIPLY, but it wouldn’t contain an instruction for AVERAGE.
In most cases, a single instruction, called an opcode, carries out a single machine operation on one or more pieces of data, called its operands. Therefore, the process of averaging two numbers would have to be broken down into two or more steps.
A machine language instruction itself might have something similar to the following format, in which an opcode is followed by several operands, which refer to the locations in the computer’s primary memory where the data are stored. The following instruction says ADD the number in LOCATION1 to the number in LOCATION2 and store the result in LOCATION3:
| Opcode | Operand 1 | Operand 2 | Operand 3 |
011110 |
110110 |
111100 |
111101 |
| (ADD) | (LOCATION 1) | (LOCATION 2) | (LOCATION 3) |
Given the primitive nature of machine language, an expression like \((a + b)/2\) would have to be translated into a sequence of several machine language instructions that, in binary code, might look as follows:
| 011110110110111100111101 |
| 000101000100010001001101 |
| 001000010001010101111011 |
In the early days of computing, before high-level languages were developed, computers had to be programmed directly in their machine languages, an extremely tedious and error-prone process. Imagine how difficult it would be to detect an error that consisted of putting a 0 in the preceding program where a 1 should occur!
Subsection 0.6.2 Translating High-level Programs
Fortunately, we no longer have to worry about machine languages, because special system software can be used to translate a high-level or source code program into machine language code or object code , which is the only code that can be executed or run by the computer.
In general, a program that translates source code to object code is known as a translator (Figure 0.6.1). Thus, with suitable translation software for Java or C++ we can write programs as if the computer could understand Java or C++ directly.
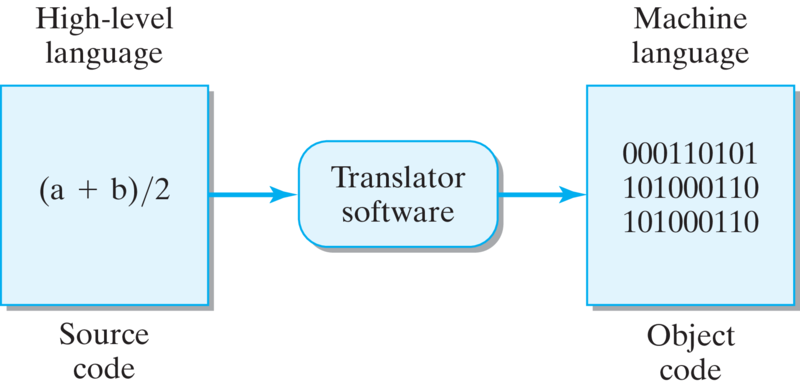
Source code translators come in two varieties. An interpreter translates a single line of source code directly into machine language and executes the code before going on to the next line of source code. A compiler translates the entire source code program into executable object code, which means that the object code can then be run directly without further translation.
There are advantages and disadvantages to both approaches. Interpreted programs generally run less efficiently than compiled programs, because they must translate and execute each line of the program before proceeding to the next line. If a line of code is repeated, an interpreter would have to translate the line each time it is encountered. By contrast, once compiled, an object program is just executed without any need for further translation.
It is also much easier to refine compiled code to make it run more efficiently. But interpreters are generally quicker and easier to develop and provide somewhat better error messages when things go wrong.
Some languages that you may have heard of, such as BASIC, LISP, Python, and Perl, are mostly used in interpreted form, although compilers are also available for these languages. Programs written in COBOL, FORTRAN, C, C++, and Pascal are compiled.
As we will see in the next section, Java programs use both compilation and interpretation in their translation process.
You have attempted of activities on this page.
