To gain some appreciation of what binary search trees are and why they are useful in implementing the Set and Map interfaces, let’s make a few comments about implementing very simple versions of these structures.
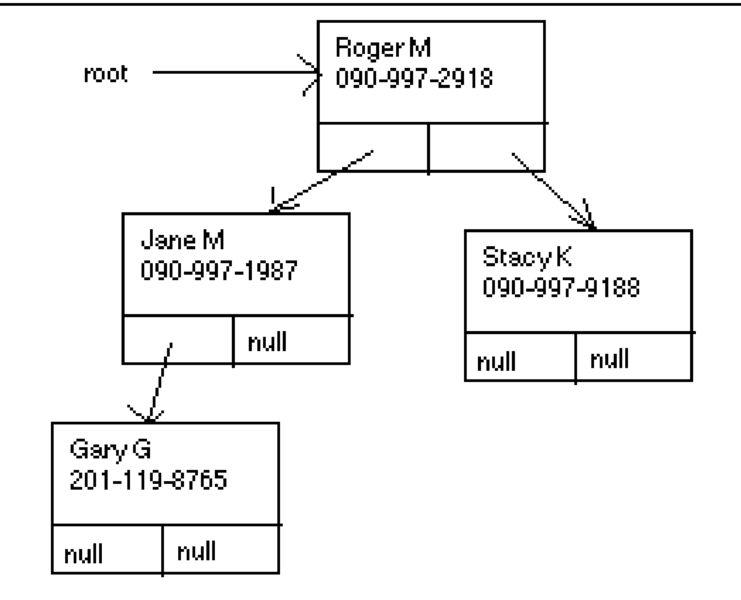
Like a linked list, a binary tree is a data structure consisting of a collection of nodes that are linked together by references from one node to another. However, unlike a linked list, each node in a binary tree contains references to two other other nodes, (left and right), corresponding to the left- and right-subtrees growing out of a particular node. A subtree is a tree that is part of larger tree. This creates a tree-like structure, as shown in Figure 16.9.1. Note that some of the references to other nodes might be null. The trunk of the tree corresponds to the node labeled root. In computer science, trees are almost always drawn upside down. Thus the trunk of the tree, root, is at the top of the figure.
If we assume that the objects contained in a tree are from a class that implements the Comparable interface, then a binary search tree is a binary tree in which the objects are ordered so that the object at a particular node is greater than the objects stored in its left subtree and less than the objects stored in its right subtree.
Figure 16.9.1. shows a binary search tree with the phone list data that we have used throughout the chapter. Objects are compared by comparing the names alphabetically. From the figure it is easy to see that searching for a object should start at the root of the tree. At each node, examining the name at the node will tell you whether you have found the object there. Otherwise, by checking the name at the node, you can decide which subtree the data could be in, and you can traverse either left or right through each level of the tree. One can deduce that if the tree is balanced—that is, if at most nodes the size of the left subtree is about the same size as the right subtree—searching the tree much faster than searching a linked list. This is one of the main advantages of using a binary search tree over a linked list.
The TreeSet and TreeMap classes implement sophisticated algorithms for inserting and removing data from a tree, which guarantees that the tree remains relatively balanced. The details of these algorithms are beyond the scope of this book, but would be a subject of study in a standard Data Structures and Algorithms course.
We will conclude this subsection by giving a brief outline of an implementation of a simple binary search tree that stores our phone list data. Like our LinkedList example, you need to define a node class and a tree class. The node class with unimplemented methods, would look like:
/**
* contains() returns true if and only if the binary tree
* which root points to has a node with its name variable
* equal to nam.
* @param nam is a string to be searched for.
* @return true if nam is contained in the tree which root
* points to.
*/
public boolean contains(String nam, String pho){
if (root == null)
return false;
else
return root.contains(nam, pho);
} // contains() in PhoneTree
The implementation of the contains() method of PhoneTreeNode is only slightly more involved. This is a recursive method that checks the name at the current node (it is first called with the root node), and if nam is alphabetically after it, it recursively looks to see if the right subtree contains it, or if it is alphabetically before it, it checks the left subtree. It is possible to implement this with a loop or recursion.
Insert a new PhoneTreeNode:
if name compared to num is <= 0:
if right is null
set right to a new PhoneTreeNode constructed with nam and pho
else
call right.insert(nam, pho) recursively
else
if left is null
set left to a new PhoneTreeNode constructed with nam and pho
else
call left.insert recursively
ExercisesSelf-Study Exercise
1.
Using the pseudocode above and the contains method as a guide, write the insert method in the PhoneTree and PhoneTreeNode. Run to test the methods with the main method below.