Say you are conducting research about bike sharing for an internship in Washington D.C. You are given the Capital Bike Sharing dataset, which contains information on Washington D.C.’s bike share program for 2011. The database has hundreds of thousands of records about every ride that anyone took and you would like to look for patterns in the data to understand questions like: “How long is the average ride?” and “Where is the most popular place to start a ride?”
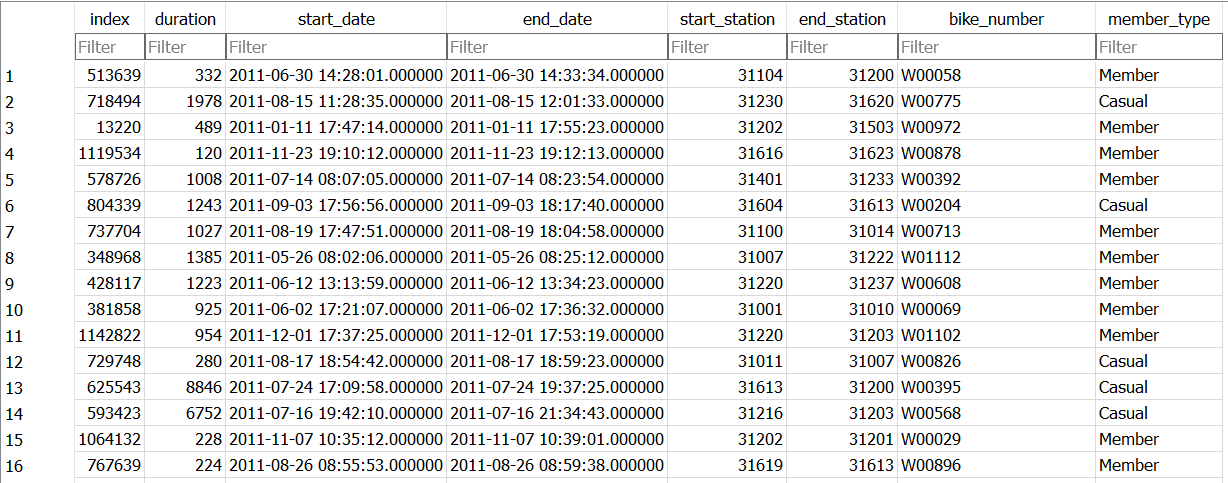
In a database, the data is arranged in tables like the one shown below. This trip_data table has all of the information about individual trips that were made. Each row in a table is a record - here, each record is an individual trip someone made.
Information about the stations is stored in a separate table called the bikeshare_stations table. In that table, each record is the information about one particular station.