
8.7. Sentiment Analysis¶
Sentiment analysis is a probabilistic evaluation of a piece of text that classifies the text as either positive, negative, or neutral. This kind of analysis is really useful in today’s online world, where everyone tweets their opinion, or complaint, or love for a movie or restaurant or an airline. Whatever the topic may be, people are constantly sharing their opinion. If you are a marketing person, or a movie producer, or a restauranteur, you want to know what people think of your product.
We’ll give you a bit of background on how this classification works, and then
we’ll use a popular Python package called nltk to produce a sentiment score
for each speech.
8.7.1. Naive Bayes¶
This is a very old technique that comes from the 1600’s, but is emerging as a very important bit of mathematics in the world of machine learning. It was the first and primary algorithm to be used in classifying email messages as spam or non-spam. The beauty of this algorithm is that it is reasonably understandable, and is well within your reach as a programming project.
For now, this introduction is a good starting point.
8.7.2. Using NLTK to Score the Speeches¶
The Natural Language ToolKit (NLTK) provides us with many tools for working with text and natural language sentences. NLTK provides a couple of different algorithms for sentiment analysis: a NaiveBayes classifier like we described above, and VADER (Valence Aware Dictionary and sEntiment Reasoner, not Darth Vader). VADER performs better on normal text and does not require us to manually train a model. So, we will use Vader as it gets us going a lot quicker.
To get started with Vader, we will need a download the data files Vader uses.
import nltk
nltk.download('vader_lexicon')
nltk.download('punkt')
Here is a function that we can use to map each of the speeches to a sentiment score.
from nltk import tokenize
from nltk.sentiment.vader import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
def score_text(text):
sentence_list = tokenize.sent_tokenize(text)
cscore = 0.0
for sent in sentence_list:
ss = analyzer.polarity_scores(sent)['compound']
cscore += ss
return cscore / len(sentence_list)
Let’s try it out on a couple of sentences to see what we get.
score_text("This movie is horrible") gives us a values of -0.5423 while
score_text("I love cute puppies") gives a score of 0.802. In fact, the
scores will always range from -1.0 to +1.0, where -1 is the most negative
sentiment and +1 is the most positive sentiment.
With our analyzer ready to go, we can add a column to the undf DataFrame
containing the sentiment score as follows.
undf['sentiment'] = undf.text.map(lambda t : score_text(t))
You can start that line running in your notebook and grab a cup of coffee; it will take a bit of time to run.
Now comes the moment of truth; let’s see the distribution of sentiment scores for all of the speeches.
import altair as alt
alt.data_transformers.enable('json')
alt.Chart(undf).mark_bar().encode(x=X('sentiment', bin=True), y='count()')
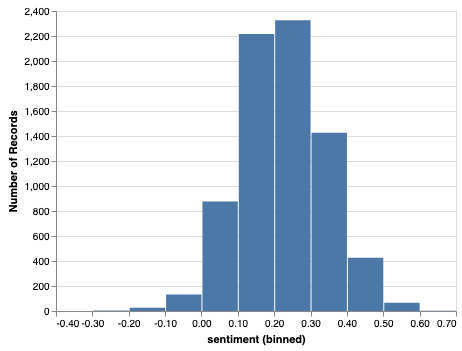
Well, it seems that the vast majority of the speeches are neutral to positive. But that may not be a big surprise, as you might expect that in the general assembly, everyone tries to be careful and diplomatic with their speeches.
If you are doing the above in colab you may need to use alt.data_transformers.disable_max_rows()
instead of alt.data_transformers.enable('json'). Both are useful when you have really large data sets
that you are visualizing. The json approach keeps the size of your notebook smaller as it stores the
data needed for visualization in a separate file. The disadvantage is that it fills up your folder with lots
of json files.
What is more interesting to investigate further are the speeches on the edges.
8.7.3. Questions for Investigation¶
Which countries are the most positive or negative in their speeches throughout the years?
Are there trends in positivity or negativity of speeches throughout the years?
What are the main topics of the most negative speeches?
What are the main topics of the most positive speeches?
Lesson Feedback
-
During this lesson I was primarily in my...
- 1. Comfort Zone
- 2. Learning Zone
- 3. Panic Zone
-
Completing this lesson took...
- 1. Very little time
- 2. A reasonable amount of time
- 3. More time than is reasonable
-
Based on my own interests and needs, the things taught in this lesson...
- 1. Don't seem worth learning
- 2. May be worth learning
- 3. Are definitely worth learning
-
For me to master the things taught in this lesson feels...
- 1. Definitely within reach
- 2. Within reach if I try my hardest
- 3. Out of reach no matter how hard I try