
8.3. Merging and Tidying Data¶
In this section, we will learn how to merge two data frames that contain information that we wish to put together. This will create a new data frame that contains the information of both data frames as long as they have a primary and foreign key, meaning they have to have a unique column in common. Then we will learn the basic principles of tidying up data and the relationships that a data set can have.
Now that we know how the file is encoded, we can read it easily.
c_codes = pd.read_csv('Data/country_codes.csv', encoding='iso-8859-1')
c_codes.head()
| country | code_2 | code_3 | country_code | iso_3166_2 | continent | sub_region | region_code | sub_region_code | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Afghanistan | AF | AFG | 4 | ISO 3166-2:AF | Asia | Southern Asia | 142.0 | 34.0 |
| 1 | Åland Islands | AX | ALA | 248 | ISO 3166-2:AX | Europe | Northern Europe | 150.0 | 154.0 |
| 2 | Albania | AL | ALB | 8 | ISO 3166-2:AL | Europe | Southern Europe | 150.0 | 39.0 |
| 3 | Algeria | DZ | DZA | 12 | ISO 3166-2:DZ | Africa | Northern Africa | 2.0 | 15.0 |
| 4 | American Samoa | AS | ASM | 16 | ISO 3166-2:AS | Oceania | Polynesia | 9.0 | 61.0 |
This DataFrame has a lot of information, and we can add all or just a bit of it
to our United Nations DataFrame using the merge method of Pandas.
Before we merge, let’s clean up the column names on the undf data frame and
rename country to code_3 to be consistent with the above.
undf.columns = ['session', 'year', 'code_3', 'text']
undf.head()
| session | year | code_3 | text | |
|---|---|---|---|---|
| 0 | 44 | 1989 | MDV | It is indeed a pleasure for me and the member... |
| 1 | 44 | 1989 | FIN | \nMay I begin by congratulating you. Sir, on ... |
| 2 | 44 | 1989 | NER | \nMr. President, it is a particular pleasure ... |
| 3 | 44 | 1989 | URY | \nDuring the debate at the fortieth session o... |
| 4 | 44 | 1989 | ZWE | I should like at the outset to express my del... |
Now, we can merge our two data frames. We will keep all the columns from the
original undf DataFrame and add country, continent, and subregion from the
c_codes DataFrame. We will merge the two data frames on the code_3
column. That is, for every row in undf, we will look for a row in the
c_codes DataFrame where the values for code_3 match. Pandas will then
add the rest of the columns from the matching row in c_codes to the current
row in undf.
In the c_codes data frame, code_3 is the “primary key”, as no two rows
have the same value for code_3. In the undf data frame, code_3 is a
“foreign key”, as we use it to look up additional information in a table where
code_3 is a primary key. More on this when we study SQL queries.
undfe = undf.merge(c_codes[['code_3', 'country', 'continent', 'sub_region']])
undfe.head()
| session | year | code_3 | text | country | continent | sub_region | |
|---|---|---|---|---|---|---|---|
| 0 | 44 | 1989 | MDV | It is indeed a pleasure for me and the member... | Maldives | Asia | Southern Asia |
| 1 | 68 | 2013 | MDV | I wish to begin by \nextending my heartfelt co... | Maldives | Asia | Southern Asia |
| 2 | 63 | 2008 | MDV | I am delivering this \nstatement on behalf of ... | Maldives | Asia | Southern Asia |
| 3 | 46 | 1991 | MDV | Allow me at the outset on behalf of the deleg... | Maldives | Asia | Southern Asia |
| 4 | 41 | 1986 | MDV | It is indeed a pleasure for me and all the mem... | Maldives | Asia | Southern Asia |
undfe[undf.code_3 == 'EU ']
/Users/bradleymiller/.local/share/virtualenvs/httlads--V2x4wK-/lib/python3.6/site-packages/ipykernel_launcher.py:1: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
"""Entry point for launching an IPython kernel.
| session | year | code_3 | text | country | continent | sub_region |
|---|
Wait! What? What happened to the EU?! Why did it disappear after the merge? What
else may have disappeared? The reason the EU disappeared is that it is not in
the c_codes data frame, and as you may recall, the merge function does
the equivalent of a set intersection. That is, the key must be in BOTH data
frames for it to be in the result. We can do our merge using an outer
join to preserve the data, then see which countries have no text and which texts
have no country name.
undfe = undf.merge(c_codes[['code_3', 'country', 'continent', 'sub_region']],
how='outer')
undfe.head()
| session | year | code_3 | text | text_len | country | continent | sub_region | |
|---|---|---|---|---|---|---|---|---|
| 0 | 44.0 | 1989.0 | MDV | It is indeed a pleasure for me and the member... | 3011.0 | Maldives | Asia | Southern Asia |
| 1 | 68.0 | 2013.0 | MDV | I wish to begin by \nextending my heartfelt co... | 2252.0 | Maldives | Asia | Southern Asia |
| 2 | 63.0 | 2008.0 | MDV | I am delivering this \nstatement on behalf of ... | 1909.0 | Maldives | Asia | Southern Asia |
| 3 | 46.0 | 1991.0 | MDV | Allow me at the outset on behalf of the deleg... | 2330.0 | Maldives | Asia | Southern Asia |
| 4 | 41.0 | 1986.0 | MDV | It is indeed a pleasure for me and all the mem... | 2630.0 | Maldives | Asia | Southern Asia |
Now let’s see which country names are not filled in.
undfe[undfe.country.isna()].code_3.unique()
array(['YDYE', 'CSK', 'YUG', 'DDR', 'EU'], dtype=object)
undfe[undfe.text.isna()].code_3.unique()
array(['ALA', 'ASM', 'AIA', 'ATA', 'ABW', 'BMU', 'BES', 'BVT', 'IOT',
'CYM', 'CXR', 'CCK', 'COK', 'CUW', 'FLK', 'FRO', 'GUF', 'PYF',
'ATF', 'GIB', 'GRL', 'GLP', 'GUM', 'GGY', 'HMD', 'HKG', 'IMN',
'JEY', 'MAC', 'MTQ', 'MYT', 'MSR', 'NCL', 'NIU', 'NFK', 'MNP',
'PCN', 'PRI', 'REU', 'BLM', 'SHN', 'MAF', 'SPM', 'SRB', 'SXM',
'SGS', 'SJM', 'TWN', 'TKL', 'TCA', 'UMI', 'VGB', 'VIR', 'WLF',
'ESH'], dtype=object)
undfe[undfe.text.isna()].country.unique()
array(['Åland Islands', 'American Samoa', 'Anguilla', 'Antarctica',
'Aruba', 'Bermuda', 'Bonaire, Sint Eustatius and Saba',
'Bouvet Island', 'British Indian Ocean Territory',
'Cayman Islands', 'Christmas Island', 'Cocos (Keeling) Islands',
'Cook Islands', 'Curaçao', 'Falkland Islands (Malvinas)',
'Faroe Islands', 'French Guiana', 'French Polynesia',
'French Southern Territories', 'Gibraltar', 'Greenland',
'Guadeloupe', 'Guam', 'Guernsey',
'Heard Island and McDonald Islands', 'Hong Kong', 'Isle of Man',
'Jersey', 'Macao', 'Martinique', 'Mayotte', 'Montserrat',
'New Caledonia', 'Niue', 'Norfolk Island',
'Northern Mariana Islands', 'Pitcairn', 'Puerto Rico', 'Réunion',
'Saint Barthélemy', 'Saint Helena, Ascension and Tristan da Cunha',
'Saint Martin (French part)', 'Saint Pierre and Miquelon',
'Serbia', 'Sint Maarten (Dutch part)',
'South Georgia and the South Sandwich Islands',
'Svalbard and Jan Mayen', 'Taiwan, Province of China', 'Tokelau',
'Turks and Caicos Islands', 'United States Minor Outlying Islands',
'Virgin Islands (British)', 'Virgin Islands (U.S.)',
'Wallis and Futuna', 'Western Sahara'], dtype=object)
Fill in the country names for YDYE, CSK, YUG, DDR, and EU by hand.
undfe.loc[undfe.code_3 == 'EU', 'country'] = 'European Union'
by_country = undfe.groupby('country',as_index=False)['text'].count()
by_country.loc[by_country.text.idxmin()]
country South Sudan
text 5
Name: 161, dtype: object
c_codes[c_codes.code_2 == 'EU']
| country | code_2 | code_3 | country_code | iso_3166_2 | continent | sub_region | region_code | sub_region_code |
|---|
I suspect that EU indicates the European Union, which has a place in the UN but is not a country.
South Sudan has only spoken 5 times. Why is that? There is a very logical explanation, but it only makes you want to check out the 5 or 10 countries that have spoken the least.
But why did EU seem to disappear? When we do a merge, if the key is missing, then the row is not included in the final result.
len(undfe)
7406
len(undf.code_3.unique())
199
len(undfe.code_3.unique())
194
set(undf.code_3.unique()) - set(undfe.code_3.unique())
{'CSK', 'DDR', 'EU', 'YDYE', 'YUG'}
Can you figure out what each of the above stands for? Why are they not in the list presented earlier?
At this point, you may want to edit the CSV file and add the data for these countries to the file. Then, you can rerun the whole notebook and we will not lose as much data.
8.3.1. Tidy Data¶
A lot of the work in data science revolves around getting data into the proper format for analysis. A lot of data comes in messy formats for many different reasons. But if we apply some basic principles from the world of database design, data modeling, and some common sense (as outlined in the Hadley Wickham paper), we can whip our data into shape. Wickham says that tidy data has the following attributes.
Each variable belongs in a column and contains values.
Each observation forms a row.
Each type of observational unit forms a table.
How does our United Nations data stack up? Pretty well. We have four columns: session, year, country, and text. If we think of the text of the speech as the thing we can observe, then each row does form an observation, and session, year, and country are attributes that identify this particular observation.
Some of the common kinds of messiness that Wickham identifies include the following.
Column headers are values not variable names. Imagine this table if we had one row for each year and a column for each country’s text! Now that would not be tidy!
Multiple variables are stored in one column. We’ve seen this untidiness in the movie data a couple of chapters ago. We’ll revisit that very soon to deal with it correctly.
Variables are stored in both rows and columns.
Multiple types of observational units are stored in the same table.
A single observational unit is stored in multiple tables.
Many of the problems with untidy data stem from not knowing how to handle relationships between multiple entities. Most of the time, things that we want to observe interact with other things we can observe, and when we try to combine them into a single data frame, that causes trouble. There are three kinds of relationships that we should consider.
one-to-one relationships
one-to-many relationships
many-to-many relationships
An example of a one-to-one relationship would be a person and their passport. A person can have one passport, and a given passport belongs to only one person. There is data that we can collect about a person and that could be stored in a DataFrame. There is also data that we can collect from a passport, such as the countries that person has visited, the place the passport was issued, and this could also be stored in a DataFrame.
An example of a one-to-many relationship is a customer and the things they have ordered from Amazon. A particular customer may have ordered many things, but a given order can only belong to a single customer.
An example of a many-to-many relationship is a student and a class. A student can be enrolled in more than one class, and a class can have many students who are enrolled in it.
Whenever you see a DataFrame that has a column that contains a list or a dictionary, that is a sure sign of untidiness. It is also something that can be fixed an in the end will make your analysis easier.
8.3.2. Tidying the Movie Genres¶
Let’s look at the genres column of the movies dataset. You may recall that it
looks odd. Here is the result of df.iloc[0].genres.
"[{'id': 16, 'name': 'Animation'}, {'id': 35, 'name': 'Comedy'}, {'id': 10751, 'name': 'Family'}]"
It looks like a list of dictionary literals, except that it is in double-quotes
like a string. Let’s first figure out how we can get it to be an actual list of
dictionaries. Then, we’ll figure out what to do with it. Python has a nifty
function called eval that allows you to evaluate a Python expression that is
a string.
eval(df.iloc[0].genres)
[{'id': 16, 'name': 'Animation'},
{'id': 35, 'name': 'Comedy'},
{'id': 10751, 'name': 'Family'}]
Even better, we can assign the result of eval to a variable, and then we can
use the list and dictionary index syntax to access parts of the result, just
like we learned about when we discussed JSON in an earlier chapter.
glist = eval(df.iloc[0].genres)
glist[1]['name']
'Comedy'
One way we could solve this is to duplicate all of the rows for as many genres as the movie has, storing one genre on each line, but that would mean we would have to needlessly duplicate all of the other information on our first movie three times.
A better strategy for solving this problem is to create a new DataFrame
with just two columns: one containing the movie’s unique id number, and a second
containing the genre. This allows you to use the merge method on the two
data frames, but only temporarily when you need to know the genre of a
particular movie.
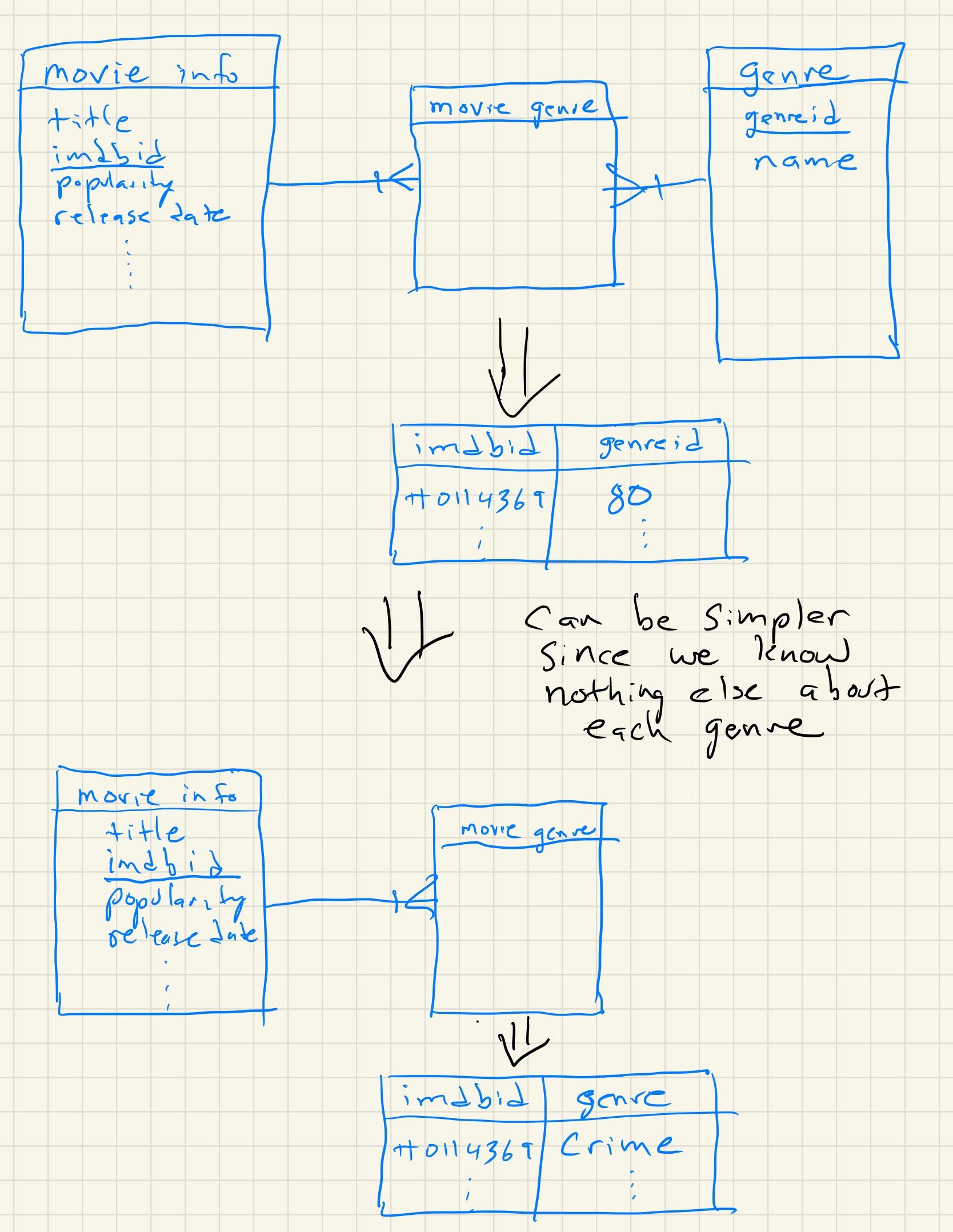
To construct this table, we need to iterate over all the rows of the DataFrame
and gather the genres for this movie. For each genre of the movie, we will add
an item to a list that contains the imdb_id of the movie and add an item to
a list that contains the name of the genre. These two lists are in sync with
each other so that the i th element of each list will represent the
same movie.
Here is some code you can use to construct the two lists.
movie_list = []
genre_list = []
def map_genres(row):
try:
glist = eval(row.genres)
except:
glist = []
print(f"bad data for {row.title}")
for g in glist:
movie_list.append(row.imdb_id)
genre_list.append(g['name'])
_ = df.apply(map_genres, axis=1)
Using these two lists, construct a new DataFrame with a column for imdb_id
and genre.
Now let’s calculate the average revenue for the Comedy genre. We’ll do this is a couple of steps.
We will reduce the genre DataFrame so it only has the Comedies left.
Then we will merge the movie data frame with the genres DataFrame using the
imdb_idcolumn.We will be left with a DataFrame that only contains the rows for the movies that are comedies. You can think of a merge like this as being the intersection of the set of comedies and the set of all movies.
Problems to work on
What is the total revenue for each genre?
What is the average vote_average for each genre?
What genre has the most votes?
Use a similar process to create a data frame of collections and their movies. Which collection has the most movies?
Again a similar process can be used for spoken_languages. How many movies are there for each language? Is English the most popular movie language?
Lesson Feedback
-
During this lesson I was primarily in my...
- 1. Comfort Zone
- 2. Learning Zone
- 3. Panic Zone
-
Completing this lesson took...
- 1. Very little time
- 2. A reasonable amount of time
- 3. More time than is reasonable
-
Based on my own interests and needs, the things taught in this lesson...
- 1. Don't seem worth learning
- 2. May be worth learning
- 3. Are definitely worth learning
-
For me to master the things taught in this lesson feels...
- 1. Definitely within reach
- 2. Within reach if I try my hardest
- 3. Out of reach no matter how hard I try