
🤔 Predicting Pizza Prices - Linear Regression¶
Linear regression is probably one of the most widely used algorithms in data science, and many other sciences. One of the best things about linear regression is that it allows us to learn from things that we know or observations and measurements of things we know to make predictions about new things. These predictions might be about the likelihood of a person buying a product online or the chance that someone will default on their loan payments. To start we are going to use an even simpler example predicting the price of pizza based on its diameter.
I have made an extensive study of the pizza places in my neighborhood and here is a table of observations of pizza diameters and their price.
Diameter |
Price |
|---|---|
6 |
7 |
8 |
9 |
10 |
13 |
14 |
17.5 |
18 |
18 |
Your first task is to make a scatter plot of the data with Altair using diameter as the x axis and price as the y axis.
What you can see pretty easily from this graph is that as the diameter of the pizza goes up, so does the price.
If you were to draw a straight line through the points that came as close as possible to all of them, it would look like this:
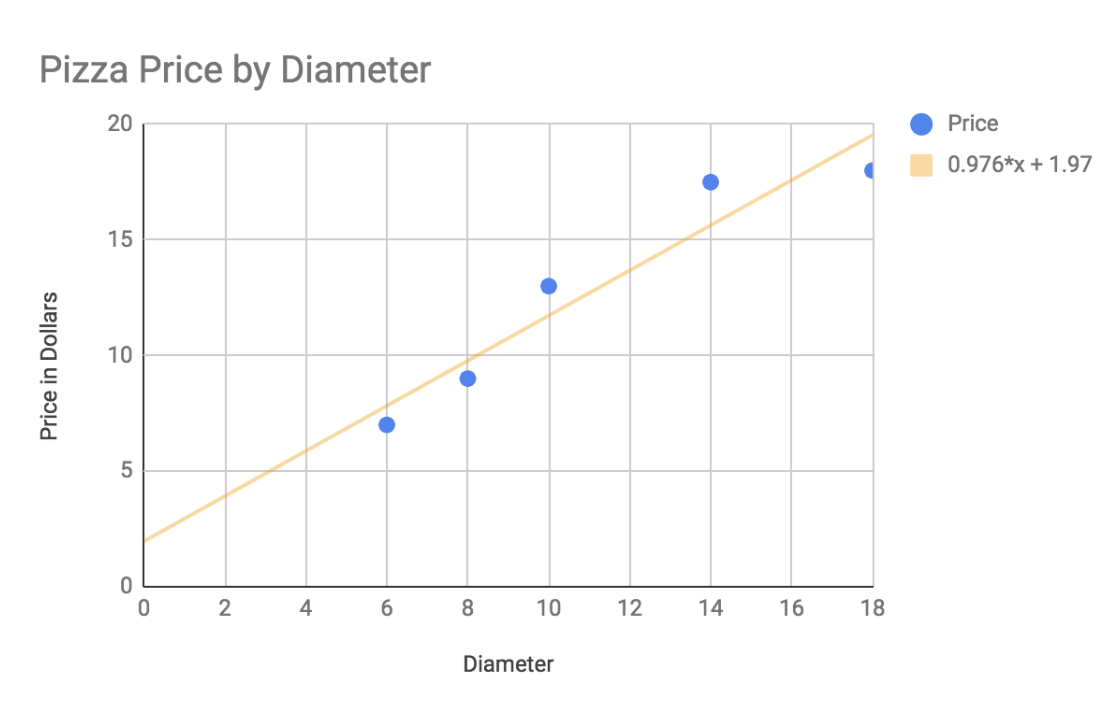
The orange line called the trend-line or the regression line is our best guess at a line that describes the data. This is important because we can come up with an equation for the line that will allow us to predict the y value (price) for any given x value (diameter). Linear regression is all about finding the best equation for the line.
How do we do that? There are actually several different ways we can come up with the equation for the line. We will look at two different solutions, one is a closed form equation that will work for any problem like this in just two dimensions. The second is a solution that will allow us to generalize the idea of a best fit line to many dimensions!
Recall the equation for a line that you learned in algebra: \(y = mx + b\) What we need to do is to determine values for m and b. One way we can do that is to simply guess! And keep refining our guesses until we get to a point where we are not really getting any better. You may think this sounds kind of stupid, but it is actually a pretty fundamental part of many machine learning algorithms. You may also be wondering how we decide what does it mean to “get better”? In the case of our pizza problem we have some data to work with, and so for a given guess for m and b we can compare the calculated y against the known value of y and measure our error. For example: Suppose we guess that b = 5 and that m = .8 for a diameter of 10 we get y = .7 x 10 + 5 or 12. Checking against our table the value should be 13 so our error is our known value minus our predicted value 13-12 or 1. If we try the same thing for a diameter of 8 we get y = .7 x 8 + 5 or 10.6 The error here is 9 - 10.6 or -1.6.
Write a Python program to calculate the values for all diameters in the original data and print them out in a table, using a slope of .7 and intercept of 5.
Now plot the original set of data along with the this new table of data. Make the original one color and your calculated table another color. Experiment with some different guesses for the slope and intercept to see how it works.
Next lets add another column to the table where we include the error. Now we have our ‘predicted values’ and a bunch of error measurements. One common way we combine these error measurements together is to compute the Mean Squared Error (MSE) This is easy to compute because all we have to do is square each of our errors, add them up and then divide by the number of error terms we have. Why do we square them first? Well, did you notice that in our example one of the errors was positive and one was negative, but when we add together both positive and negative numbers they tend to cancel each other out making our final mean value smaller. So we square them to be sure they are all positive. We call this calculation of the MSE an objective function. In many machine learning algorithms our goal is to minimize the objective function. That is what we want to do here, we want to find the value for m and b that minimizes the error.
To do this we will follow these steps:
Pick a random value for m and b
Compute the MSE for all our known points
Repeat the following steps 1000 times 1. Make m slightly bigger and recompute the MSE does that make it smaller? If so then use this new value for m. If it doesn’t make MSE smaller than make m slightly smaller and see if that helps. 1. Make b slightly bigger and recompute the MSE does that make it smaller? If so then use this new value for b and go back to step 3a. If not then try a slightly smaller b and see if that makes the MSE smaller if so keep this value for b and go back to step 3a.
After repeating the above enough times we will be very close to the best possible values for m and b. We can now use these values to make predictions for other pizzas where we know the diameter but don’t know the price.
Let’s develop some intuition for this whole thing by writing a function and trying to minimize the error.
You will write three functions compute_y(x, m, b), compute_all_y(list_of_x) This shoudl use compute_y and compute_mse(list_of_known, list_of_predictions)
Next write a function that systematically tries different values for m and b in order to minimize the MSE. Put this function in a loop for 1000 times and see what your value is for m and b at the end.
Congratulations! You have just written your first “machine learning” algorithm. One fun thing you can do is to save the MSE at the end of each time through the loop then plot it. You should see the error go down pretty quickly and then level off or go down very gradually. Note that the error will ever go to 0 because the data isn’t perfectly linear. Nothing in the real world is!
At this point your algorithms ability to ‘learn’ is limited by how much you change the slope and intercept values each time through the loop. At the beginning its good to change them by a lot but as you get closer to the best answer its better to tweak them by smaller and smaller amounts. Can you adjust your code above to do this?
For two dimensional data there is even a closed form solution to this problem that one could derive using a bit of calculus. It is worthwhile to have the students do this to see that their solution is very very close to the solution you get from a simple formula that slope = covariance / variance and intercept = avg(y) - slope * avg(x). Write a function that will calculate the slope and intercept using this method and compare the slope and intercept with your previous error.
Try it out on Other Data¶
Now that you have the regression algorithm working on this toy data set, try it out on another data set. Something larger would be good. But here is one suggestion for a next step. It is said that there is a correlation between the number of times a cricket chirps and the temperature.
crickets_train.csvchirps/min,temp 19.79999924,93.30000305 18.39999962,84.30000305 17.10000038,80.59999847 15.5,75.19999695 14.69999981,69.69999695 17.10000038,82 15.39999962,69.40000153 16.20000076,83.30000305 17.20000076,82.59999847 16,80.59999847 17,83.5 14.39999962,76.30000305
crickets_test.csvchirps/min,temp 20,88.59999847 16,71.59999847 15,79.59999847
Find the best slope and intercept using the crickets_train.csv file. Then use the slope and intercept to make predictions using the number of chirps in the crickets_test.csv file. You can see how well you did with this data because you also have a known temperature to compare it to.
You might try this on a dataset with 100 or more rows of data just to see how long it takes to find a good slope and intercept.
Post Project Questions
-
During this project I was primarily in my...
- 1. Comfort Zone
- 2. Learning Zone
- 3. Panic Zone
-
Completing this project took...
- 1. Very little time
- 2. A reasonable amount of time
- 3. More time than is reasonable
-
Based on my own interests and needs, the things taught in this project...
- 1. Don't seem worth learning
- 2. May be worth learning
- 3. Are definitely worth learning
-
For me to master the things taught in this project feels...
- 1. Definitely within reach
- 2. Within reach if I try my hardest
- 3. Out of reach no matter how hard I try