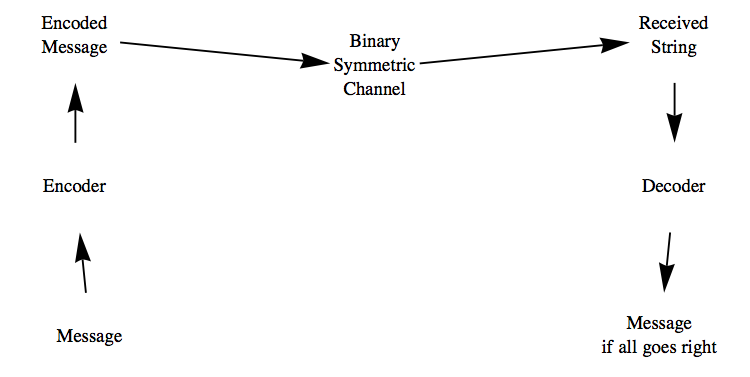
The encoding that we will consider here takes a block
\(a = \left(a_1, a_2, a_3 \right)\) and produces a code word of length 6. As in the triple repetition code, each code word will differ from each other code word by at least three bits. As a result, any single error will not push a code word close enough to another code word to cause confusion. Now for the details.
Let
\begin{equation*}
G=\left(
\begin{array}{cccccc}
1 & 0 & 0 & 1 & 1 & 0 \\
0 & 1 & 0 & 1 & 0 & 1 \\
0 & 0 & 1 & 0 & 1 & 1 \\
\end{array}
\right).
\end{equation*}
We call \(G\) the generator matrix for the code, and let \(a = \left(a_1, a_2, a_3 \right)\) be our message. Define \(e : \mathbb{Z}_2{}^3 \to \mathbb{Z}_2{}^6\) by
\begin{equation*}
e(a) = a G = \left(a_1, a_2, a_3,a_4, a_5, a_6\right)
\end{equation*}
where
\begin{equation*}
\begin{array}{r@{}r@{}r@{}r@{}r@{}r@{}r@{}}
a_4 &= & a_1 & {}+_2{} & a_2 & & \\
a_5 &= & a_1 & & &{}+_2{} & a_3 \\
a_6 &= & & & a_2 &{}+_2{} & a_3 \\
\end{array}
\end{equation*}
Notice that since matrix multiplication is distributive over addition, we have
\begin{equation*}
e(a + b)= (a+b)G = aG + bG = e(a)+e(b)
\end{equation*}
for all \(a, b \in \mathbb{Z}_2{}^3\text{.}\) This equality, may look familiar from the definition of an isomorphism, but in this case the function \(e\) is not onto. If you’ve read about homomorphisms, this is indeed an example of one.
One way to see that any two distinct code words have a distance from one another of at least 3 is to consider the images of any two distinct messages. If \(a\) and \(b\) are distinct elements of \(\mathbb{Z}_2{}^3\text{,}\) then \(c = a + b\) has at least one coordinate equal to 1. Now consider the difference between \(e(a)\) and \(e(b)\text{:}\)
\begin{equation*}
\begin{split}
e(a) + e(b) &= e(a + b) \\
& = e(c)\\
\end{split}
\end{equation*}
Whether \(c\) has 1, 2, or 3 ones, \(e(c)\) must have at least three ones. This can be seen by considering the three cases separately. For example, if \(c\) has a single one, two of the parity bits are also 1. Therefore, \(e(a)\) and \(e(b)\) differ in at least three bits. By the same logic as with triple repetition, a single bit error in any code word produces an element of the code space that is contained in one of the balls of radius 1 centered about a code word.
Now consider the problem of decoding received transmissions. Imagine that a code word, \(e(a)\text{,}\) is transmitted, and \(b= \left(b_1, b_2, b_3,b_4, b_5, b_6\right)\) is received. At the receiving end, we know the formula for \(e(a)\text{,}\) and if no error has occurred in transmission,
\begin{equation*}
\begin{array}{c}
b_1= a_1 \\
b_2=a_2 \\
b_3=a_3 \\
b_4=a_1+_2a_2 \\
b_5=a_1+_2a_3 \\
b_6=a_2+_2a_3 \\
\end{array}
\Rightarrow
\begin{array}{r@{}r@{}r@{}r@{}r@{}r@{}r@{}r@{}r@{}r@{}r@{}r@{}}
b_1 & +_2 & b_2 & & &+_2& b_4& & & & &=0\\
b_1 & & & +_2 &b_3& & & +_2& b_5 & & &=0\\
& & b_2 & +_2 &b_3& & & & &+_2 &b_6&=0\\
\end{array}
\end{equation*}
The three equations on the right are called parity-check equations. If any of them are not true, an error has occurred. This error checking can be described in matrix form.
Let
\begin{equation*}
H=\left(
\begin{array}{ccc}
1 & 1 & 0 \\
1 & 0 & 1 \\
0 & 1 & 1 \\
1 & 0 & 0 \\
0 & 1 & 0 \\
0 & 0 & 1 \\
\end{array}
\right)
\end{equation*}
The matrix
\(H\) is called the parity-check matrix for this code. Now define
\(p:\mathbb{Z}_2{}^6 \to \mathbb{Z}_2{}^3\) by
\(p(b) = b H\text{.}\) We call
\(p(b)\) the
syndrome of the received block. For example,
\(p(0,1,0,1,0,1)=(0,0,0)\) and
\(p(1,1,1,1,0,0)=(1,0,0)\)
Note that
\(p\) has a similar property as
\(e\text{,}\) that
\(p(b_1+b_2)=p(b_1)+p(b_2)\text{.}\) If the syndrome of a block is
\((0, 0, 0)\text{,}\) we can be almost certain that the message block is
\(\left(b_1, b_2, b_3\right)\text{.}\)
Next we turn to the method of correcting errors. Despite the fact that there are only eight code words, one for each three-bit block value, the set of possible received blocks is \(\mathbb{Z}_2{}^6\text{,}\) with 64 elements. Suppose that \(b\) is not a code word, but that it differs from a code word by exactly one bit. In other words, it is the result of a single error in transmission. Suppose that \(w\) is the code word that \(b\) is closest to and that they differ in the first bit. Then \(b + w = (1, 0, 0, 0, 0, 0)\) and
\begin{equation*}
\begin{split}
p(b) & = p(b) + p(w)\quad \textrm{ since }p(w) = (0, 0, 0)\\
&=b H + w H \\
&=(b+w)H\quad \textrm{ by the distributive property}\\
&=p(b+w)\\
& =p(1,0,0,0,0,0)\\
& =(1,1,0)\\
\end{split}
\end{equation*}
This is the first row of \(H\text{!}\)
Note that we haven’t specified
\(b\) or
\(w\text{,}\) only that they differ in the first bit. Therefore, if
\(b\) is received, there was probably an error in the first bit and
\(p(b)= (1, 1, 0)\text{,}\) the transmitted code word was probably
\(b + (1, 0, 0, 0, 0, 0)\) and the message block was
\(\left(b_1+_2 1, b_2, b_3\right)\text{.}\) The same analysis can be done if
\(b\) and
\(w\) differ in any of the other five bits.
In general, if the syndrome of a received string of bits is the
\(k\)th row of the parity check matrix, the error has occurred in the
\(k\)th bit.