
13.13. Group Work on BeautifulSoup with Requests¶
It is best to use a POGIL approach with the following. In POGIL students work in groups on activities and each member has an assigned role. For more information see https://cspogil.org/Home.
Note
If you work in a group, have only one member of the group fill in the answers on this page. You will be able to share your answers with the group at the bottom of the page.
Learning Objectives
Students will know and be able to do the following.
Content Objectives:
Import the necessary libraries
Use requests to get the HTML from a URL
Create a soup object from the HTML
Use
findandfind_allto get data from a soup objectUse
class_to find data with a particular CSS classGet the text of a tag using
tag.textGet the value for an attribute from a tag using
tag.get(attribute)
Process Objectives:
Put code in order.
Modify code to produce the correct output.
13.13.1. Getting a tag from a soup object¶
BeautifulSoup makes it easy to extract
the data you need from an HTML or XML page. It creates a soup object that
contains all the tags in the page. You can use find or find_all to find
either the first of a type of a tag or a list of a type of tag.
We will use the requests library to get a response object from a URL,
create a BeautifulSoup object from the HTML content in the response,
use find to find the first paragraph tag, and then
print the first paragraph tag.
This will find and print the first paragraph tag from the Michigan Daily site. It will interpret the tag as HTML and show just the text of the tag.
The html.parser is the HTML parser that is included in the standard Python 3 library.
It is used to parse the HTML into a tree of tags.
Information on other HTML parsers is available at:
http://www.crummy.com/software/BeautifulSoup/bs4/doc/#installing-a-parser
Put the following blocks in order to print the second paragraph from the Michigan Daily website. It uses the find_all method on
BeautifulSoup to get a list of all of the paragraphs.
13.13.2. Getting text from a tag¶
Some tags have text like a paragraph tag or a span tag. You can use tagName.text to get the text.
You can also find a tag with a particular CSS class.
This will print the text for the site description paragraph.
Note
When you specify a CSS class you must use class_ as the keyword. This is becuase class is already
a keyword that is used to define a new class in Python.
Put the following blocks in order to print the text for span tag which is a child of a h3 tag with a class of css-1pjbq1w.
13.13.4. How to Find Tags Inside of Tags¶
Sometimes the tags that you want to find don’t have a particular class that makes it easy to find them. Then you can find a parent tag with a particular class and then use that tag to look for the child tag you want.
Note
You can use ‘find_all’ to get a list of all tags of a type and then loop through those tags and get the first tag of a type.
You will typically first inspect a webpage to determine how to find what you are looking for in the page. You can do that with the developer tools in the Chrome browser. Click on the three dots on the top right of the page and then “More Tools” and then “Developer Tools”. You you can also just right-click on what you are interested in viewing on a webpage, and then click on “Inspect”.
You will see the HTML source for the thing you inspected.
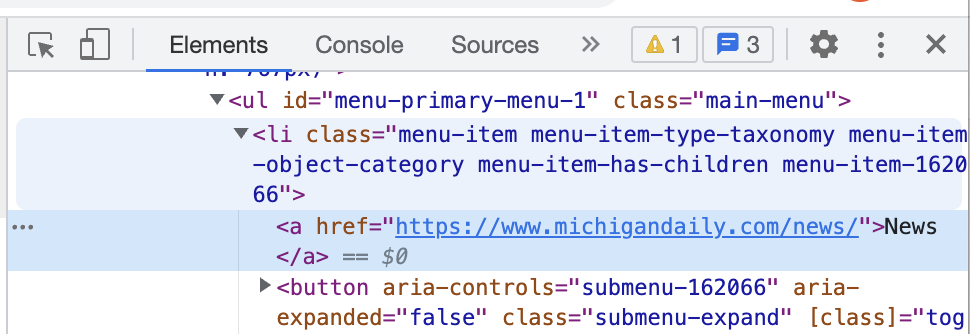
You can use this information to find a parent tag such as the “li” tag that contains the “a” tag in the nagivation bar in the Michigan Daily webpage. Use find_all to get all the “li” tags and then loop through those tags and use find to get the first “a” tag in each “li” tag.
Note
You don’t have to use all the classes that a tag has. Try to find a class that is specific to the tags you are looking for.
Put the following blocks in order to print the href for the first ‘a’ tag in each h2 tag with a class of “entry-title”
The Michigan Daily has a “Most Read” section. It is in a “div” tag with a class of “jetpack_top_posts_widget”. Inside that tag there are “li” (list item) tags. In each “li” tag is an “a” tag.
Complete the code below to print the href values for the “a” tags in the “Most Read” section.
If you worked in a group, you can copy the answers from this page to the other group members. Select the group members below and click the button to share the answers.
The Submit Group button will submit the answer for each each question on this page for each member of your group. It also logs you as the official group submitter.