
4.6. Implementing an Ordered Linked List¶
In order to implement the ordered linked list, we must remember that the relative positions of the items are based on some underlying characteristic. The ordered linked list of integers given above (17, 26, 31, 54, 77, and 93) can be represented by a linked structure as shown in Figure 15. Again, the node and link structure is ideal for representing the relative positioning of the items.

Figure 15: An Ordered Linked List¶
To implement the OrderedList class, we will use the same technique
as seen previously with unordered linked lists. Once again, an empty linked list will
be denoted by a head reference to NULL (see
Listing 8).
Listing 8
class OrderedList {
Node* head;
}
As we consider the operations for the ordered linked list, we should note that
the isEmpty and size methods can be implemented the same as
with unordered linked lists since they deal only with the number of nodes in
the linked list without regard to the actual item values. Likewise, the
remove method will work just fine since we still need to find the
item and then link around the node to remove it. The two remaining
methods, search and add, will require some modification.
The search of an unordered linked list required that we traverse the
nodes one at a time until we either find the item we are looking for or
run out of nodes (NULL). It turns out that the same approach would
actually work with the ordered linked list and in fact in the case where we
find the item it is exactly what we need. However, in the case where the
item is not in the linked list, we can take advantage of the ordering to stop
the search as soon as possible.
For example, Figure 16 shows the ordered linked list as a
search is looking for the value 45. As we traverse, starting at the head
of the linked list, we first compare against 17. Since 17 is not the item we
are looking for, we move to the next node, in this case 26. Again, this
is not what we want, so we move on to 31 and then on to 54. Now, at this
point, something is different. Since 54 is not the item we are looking
for, our former strategy would be to move forward. However, due to the
fact that this is an ordered linked list, that will not be necessary. Once the
value in the node becomes greater than the item we are searching for,
the search can stop and return False. There is no way the item could
exist further out in the linked list.
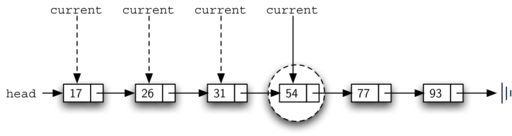
Figure 16: Searching an Ordered Linked List¶
Listing 9 shows the complete search method. It is
easy to incorporate the new condition discussed above by adding another
boolean variable, stop, and initializing it to False (line 4).
While stop is False (in other words, while the search is still ongoing) we can continue to look
forward in the linked list (line 5). If any node is ever discovered that
contains data greater than the item we are looking for, we will set
stop to True (lines 9–10). The remaining lines are identical to
the unordered linked list search.
Listing 9
bool search(int item) {
Node *current = head;
bool found = false;
bool stop = false;
while (current != NULL && !found && !stop) {
if (current->getData() == item) {
found = true;
} else {
if (current->getData() > item) {
stop = true;
} else {
current = current->getNext();
}
}
}
return found;
}
The most significant method modification will take place in add.
Recall that for unordered linked lists, the add method could simply place a
new node at the head of the linked list. It was the easiest point of access.
Unfortunately, this will no longer work with ordered linked lists. It is now
necessary that we discover the specific place where a new item belongs
in the existing ordered linked list.
Assume we have the ordered linked list consisting of 17, 26, 54, 77, and 93 and
we want to add the value 31. The add method must decide that the new
item belongs between 26 and 54. Figure 17 shows the setup
that we need. As we explained earlier, we need to traverse the linked
list looking for the place where the new node will be added. We know we
have found that place when either we run out of nodes (current
becomes NULL) or the value of the current node becomes greater than
the item we wish to add. In our example, seeing the value 54 causes us
to stop.
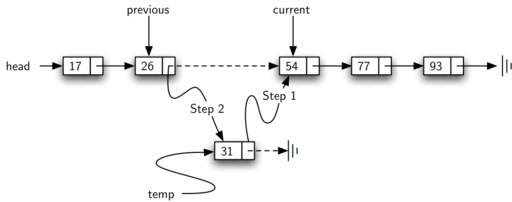
Figure 17: Adding an Item to an Ordered Linked List¶
As we saw with unordered linked lists, it is necessary to have an additional
reference, again called previous, since current will not provide
access to the node that must be modified. Listing 10 shows
the complete add method. Lines 2–3 set up the two external
references and lines 9–10 again allow previous to follow one node
behind current every time through the iteration. The condition (line
5) allows the iteration to continue as long as there are more nodes and
the value in the current node is not larger than the item. In either
case, when the iteration fails, we have found the location for the new
node.
The remainder of the method completes the two-step process shown in
Figure 17. Once a new node has been created for the item,
the only remaining question is whether the new node will be added at the
beginning of the linked list or some place in the middle. Again,
previous == NULL (line 13) can be used to provide the answer.
Listing 10
void add(int item) {
if (head == NULL) {
Node *newNode = new Node(item);
head = newNode;
} else {
Node *current = head;
Node *previous = NULL;
bool stop = false;
while (current != NULL && !stop) {
if (current->getData() > item) {
stop = true;
} else {
previous = current;
current = current->getNext();
}
}
Node *temp = new Node(item);
if (previous == NULL) {
temp->setNext(head);
head = temp;
} else {
temp->setNext(current);
previous->setNext(temp);
}
}
}
The OrderedList class with methods discussed thus far can be found
in ActiveCode 1.
We leave the remaining methods as exercises. You should carefully
consider whether the unordered implementations will work given that the
linked list is now ordered.
4.6.1. Analysis of Linked Lists¶
To analyze the complexity of the linked list operations, we need to
consider whether they require traversal. Consider a linked list that has
n nodes. The isEmpty method is \(O(1)\) since it requires
one step to check the head reference for NULL. size, on the
other hand, will always require n steps since there is no way to know
how many nodes are in the linked list without traversing from head to
end. Therefore, size is \(O(n)\). Adding an item to an
unordered linked list will always be O(1) since we simply place the new node at
the head of the linked list. However, search and remove, as well
as add for an ordered linked list, all require the traversal process.
Although on average they may need to traverse only half of the nodes,
these methods are all \(O(n)\) since in the worst case each will
process every node in the linked list.
-
Q-2: Match the Big O() analysis to their corresponding opperation.
Try again!
- O(1)
- isEmpty, add (unordered linked list)
- O(n)
- length,add, search, and remove(ordered linked list)
- In a circular linked list, the head Node of the linked list contains a pointer to the last node in the list.
- Wrong! the head Node of the list will only contain a pointer to the second Node.
- In a circular linked list, the last Node of the linked list contains a pointer to the head node of the list rather than pointing to NULL.
- Correct! the final Node of the linked list will contain a pointer to the first node so that it is possible to make "circles" around the list.
- In a circular linked list, every node contains a pointer to the head of the list, making it possible to return back to the beginning of the list at any time.
- Wrong! None of the nodes in the middle of the list will ever point to the head node in a circular linked list.
- In a circular linked list, the head and final Node of the linked list point to each other, making it possible to traverse through the list in both directions.
- Hint: This would be possible in a circular doubly linked list, but not a circular linked list.
Q-3: After having read over unordered and ordered linked lists, what do you think a circular linked list would do differently from an ordered or unordered linked list? (Hint: think about the example from the beginning of the chapter.)