
5.5. Transformación de claves (hashing)¶
En secciones anteriores pudimos hacer mejoras en nuestros algoritmos de búsqueda aprovechando la información acerca de dónde se almacenan los ítems en la colección con respecto a los demás. Por ejemplo, al saber que se ordenó una lista, podríamos buscar en tiempo logarítmico usando una búsqueda binaria. En esta sección intentaremos ir un paso más allá construyendo una estructura de datos en la que se pueda buscar en tiempo \(O(1)\). Este concepto se conoce como búsqueda por transformación de claves (o hashing en inglés).
Para hacer esto, necesitaremos saber aún más sobre dónde podrían estar los ítems cuando vamos a buscarlos en la colección. Si cada ítem está donde debe estar, entonces la búsqueda puede usar una sola comparación para descubrir la presencia de un ítem. Veremos, sin embargo, que éste no suele ser el caso.
Una tabla hash es una colección de ítems que se almacenan de tal manera que sea más fácil encontrarlos más tarde. Cada posición de la tabla hash, a menudo llamada una ranura, puede contener un ítem y se llama por un valor entero comenzando en 0. Por ejemplo, tendremos una ranura llamada 0, una ranura llamada 1, una ranura llamada 2, y así sucesivamente. Inicialmente, la tabla hash no contiene ningún ítem por lo que cada ranura está vacía. Podemos implementar una tabla hash usando una lista con cada ítem inicializado con el valor especial de Python None. La Figura 4 muestra una tabla hash de tamaño \(m=11\). En otras palabras, hay m ranuras en la tabla, con nombres de 0 a 10.

Figura 4: Tabla hash con 11 ranuras vacías¶
Figura 4: Tabla hash con 11 ranuras vacías
La correspondencia entre un ítem y la ranura a donde pertenece ese ítem en la tabla hash se denomina la función hash. La función hash tomará cualquier ítem de la colección y devolverá un número entero en el rango de nombres de las ranuras, entre 0 y m-1. Supongamos que tenemos el conjunto de ítems enteros 54, 26, 93, 17, 77 y 31. Nuestra primera función hash, a veces denominada “método del residuo”, simplemente toma un ítem y lo divide por el tamaño de la tabla, devolviendo el residuo como su valor hash (\(h(item)=item \% 11\)). La Tabla 4 da todos los valores hash para nuestros ítems de ejemplo. Tenga en cuenta que este método del residuo (módulo aritmético) estará típicamente presente en alguna forma en todas las funciones hash, ya que el resultado debe estar en el rango de nombres de las ranuras.
Ítem |
Valor hash |
|---|---|
54 |
10 |
26 |
4 |
93 |
5 |
17 |
6 |
77 |
0 |
31 |
9 |
Una vez calculados los valores hash, podemos insertar cada ítem en la tabla hash en la posición designada como se muestra en la Figura 5. Note que 6 de las 11 ranuras están ocupadas. Esto se conoce como el factor de carga, y es denotado comúnmente por \(\lambda = \frac {numeroDeItems}{tamanoTabla}\). Para este ejemplo, \(\lambda = \frac {6}{11}\).

Figura 5: Tabla hash con seis ítems¶
Figura 5: Tabla hash con seis ítems
Ahora, cuando queramos buscar un ítem, simplemente usamos la función hash para calcular el nombre de la ranura para el ítem y luego verificamos la tabla hash para ver si está presente. Esta operación de búsqueda es \(O(1)\), ya que se requiere una cantidad de tiempo constante para calcular el valor hash y luego indizar la tabla hash en esa ubicación. Si todo está donde debería estar, hemos encontrado un algoritmo de búsqueda de tiempo constante.
Usted probablemente ya puede ver que esta técnica sólo va a funcionar si a cada ítem le corresponde una ubicación exclusiva en la tabla hash. Por ejemplo, si el ítem 44 hubiera sido el siguiente ítem de nuestra colección, tendría un valor hash de 0 (\(44 \% 11 = 0\)). Dado que 77 también tenía un valor hash de 0, tendríamos un problema. Según la función hash, dos o más ítems necesitarían estar en la misma ranura. Esto se conoce como colisión (también se puede llamar un “choque”). Evidentemente, las colisiones crean un problema para la técnica de búsqueda por transformación de claves. Las discutiremos en detalle más adelante.
5.5.1. Funciones hash¶
Dada una colección de ítems, una función hash que asigna cada ítem en una ranura única se conoce como una función hash perfecta. Si conociéramos los ítems y la colección nunca cambiara, entonces sería posible construir una función hash perfecta (consulte los ejercicios para obtener más información sobre las funciones hash perfectas). Desafortunadamente, dada una colección arbitraria de ítems, no existe una forma sistemática de construir una función hash perfecta. Afortunadamente, no necesitamos que la función hash sea perfecta para aún obtener una mayor eficiencia de desempeño.
Una forma de tener siempre una función hash perfecta es aumentar el tamaño de la tabla hash para que cada valor posible se pueda acomodar en el rango de ítems. Esto garantiza que cada ítem tendrá una ranura exclusiva. Aunque esto es práctico para un número pequeño de ítems, no es factible cuando el número de ítems posibles es grande. Por ejemplo, si los ítems fueran números de Seguridad Social de nueve dígitos, este método requeriría casi mil millones de ranuras. Si sólo queremos almacenar datos para un grupo de 25 estudiantes, estaríamos desperdiciando una enorme cantidad de memoria.
Nuestro objetivo es crear una función hash que minimice el número de colisiones, sea fácil de calcular y distribuya uniformemente los ítems en la tabla hash. Hay varias maneras comunes de extender el método simple del residuo. Vamos a considerar aquí algunas de ellas.
El método de plegado para construir las funciones hash comienza dividiendo el ítem en partes del mismo tamaño (la última parte puede que no sea del mismo tamaño). Luego se suman estas partes para obtener el valor hash resultante. Por ejemplo, si nuestro ítem era el número telefónico 436-555-4601, tomaríamos los dígitos y los dividiríamos en grupos de 2 (43,65,55,46,01). Después de la suma \(43+65+55+46+01\), obtendremos 210. Si asumimos que nuestra tabla hash tiene 11 ranuras, entonces necesitamos realizar el paso adicional de dividir entre 11 y recordar el residuo. En este caso \(210\ \%\ 11\) es 1, por lo que el número telefónico 436-555-4601 se asigna a la ranura 1. Algunos métodos de plegado van un paso más allá e invierten cada una de las otras partes antes de la suma. Para el ejemplo anterior obtendríamos \(43+56+55+64+01 = 219\) lo cual da \(219\ \%\ 11 = 10\).
Otra técnica numérica para construir una función hash se denomina el método del centro del cuadrado. En primer lugar elevamos el ítem al cuadrado, y luego extraemos cierta parte de los dígitos resultantes. Por ejemplo, si el ítem fuera 44, primero calcularíamos \(44^{2} = 1,936\). Extrayendo los dos dígitos centrales, 93, y realizando el paso restante, obtendríamos 5 (\(93\ \%\ 11\)). La Tabla 5 muestra las correspondencias de los ítems tanto con el método del residuo como con el método del centro del cuadrado. Verifique que usted entiende cómo se calcularon estos valores.
Ítem |
Residuo |
Centro del cuadrado |
|---|---|---|
54 |
10 |
3 |
26 |
4 |
7 |
93 |
5 |
9 |
17 |
6 |
8 |
77 |
0 |
4 |
31 |
9 |
6 |
También podemos crear funciones hash para ítems basados en caracteres tales como las cadenas. La cadena “cat” puede pensarse como una secuencia de valores ordinales.
>>> ord('c')
99
>>> ord('a')
97
>>> ord('t')
116
Podemos entonces tomar estos tres valores ordinales, sumarlos y usar el método del residuo para obtener un valor hash (vea la Figura 6). El Programa 1 muestra una función llamada hash que toma una cadena y un tamaño de tabla y devuelve el valor hash correspondiente en el rango de 0 a tamanoTabla-1.
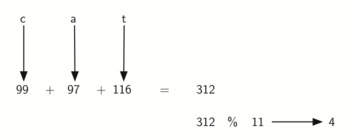
Figura 6: Transformación de claves (hashing) de una cadena usando valores ordinales¶
Figura 6: Transformación de claves (hashing) de una cadena usando valores ordinales
Programa 1
def hash(unaCadena, tamanoTabla):
suma = 0
for pos in range(len(unaCadena)):
suma = suma + ord(unaCadena[pos])
return suma%tamanoTabla
Es interesante observar que al usar esta función hash, los anagramas siempre tendrán el mismo valor hash. Para remediar esto, podríamos usar la posición del carácter como un peso o ponderación. La Figura 7 muestra una posible forma de utilizar el valor de la posición como factor de ponderación. La modificación de la función hash se deja como un ejercicio.
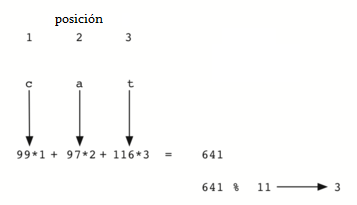
Figura 7: Transformación de claves de una cadena usando valores ordinales con ponderación¶
Figura 7: Transformación de claves de una cadena usando valores ordinales con ponderación
Tal vez usted sea capaz de pensar en una serie de formas adicionales para calcular valores hash para los ítems en una colección. Lo importante de recordar es que la función hash tiene que ser eficiente para que no se convierta en la parte dominante del proceso de almacenamiento y búsqueda. Si la función hash es demasiado compleja, entonces se vuelve más trabajoso calcular el nombre de la ranura de lo que costaría simplemente hacer una búsqueda secuencial básica o una búsqueda binaria como se describió anteriormente. Esto invalidaría rápidamente el propósito de la transformación de claves.
5.5.2. Solución de colisiones¶
Ahora regresamos al problema de las colisiones. Cuando a dos ítems se les asigna la misma ranura, debemos contar con un método sistemático para colocar el segundo ítem en la tabla hash. Este proceso se denomina solución de colisiones. Como dijimos anteriormente, si la función hash es perfecta, nunca se producirán colisiones. Sin embargo, como esto no suele ser posible, la solución de colisiones se convierte en una parte muy importante de la transformación de claves.
Un método para solucionar las colisiones examina la tabla hash e intenta encontrar otra ranura disponible para contener el ítem que causó la colisión. Una manera sencilla de hacerlo es comenzar en la posición del valor hash original y luego moverse secuencialmente a lo largo de las ranuras hasta encontrar la primera que esté vacía. Tenga en cuenta que es posible que necesite volver a la primera ranura (circularmente) para cubrir toda la tabla hash. Este proceso de solución de colisiones se conoce como direccionamiento abierto ya que intenta encontrar la siguiente ranura o dirección disponible (“abierta”) en la tabla hash. Al visitar sistemáticamente cada una de las ranuras, de una en una, estamos ejecutando una técnica de direccionamiento abierto llamada prueba lineal.
La Figura 8 muestra un conjunto extendido de ítems enteros según la función hash del método simple del residuo (54, 26, 93, 17, 77, 31, 44, 55, 20). La Tabla 4 muestra el contenido original. Cuando intentamos colocar el 44 en la ranura 0, se produce una colisión. Según la técnica de prueba lineal, miramos secuencialmente, ranura por ranura, hasta encontrar una posición disponible. En este caso, encontramos la ranura 1.
Una vez más, el 55 debe ir en la ranura 0, pero debe ser colocado en la ranura 2, ya que ésa es la siguiente posición disponible. El valor final, 20, debería ubicarse en la ranura 9. Dado que la ranura 9 está llena, comenzamos a realizar la prueba lineal. Visitamos las ranuras 10, 0, 1 y 2 y finalmente encontramos una ranura vacía en la posición 3.

Figura 8: Solución de colisiones con prueba lineal¶
Figura 8: Solución de colisiones con prueba lineal
Una vez que hemos construido una tabla hash utilizando direccionamiento abierto y prueba lineal, es esencial que utilicemos los mismos métodos para buscar ítems. Supongamos que queremos buscar el ítem 93. Cuando calculamos el valor hash, obtenemos 5. Al mirar en la ranura 5 confirmamos que está el 93, y podemos devolver True. ¿Qué pasaría si estamos buscando el 20? Ahora el valor hash es 9 y en la ranura 9 está almacenado el 31. No podemos simplemente devolver False, ya que sabemos que podría haber habido colisiones. Ahora nos vemos obligados a hacer una búsqueda secuencial, comenzando en la posición 10, buscando hasta que encontremos el ítem 20 o encontremos una ranura vacía.
Una desventaja de la prueba lineal es la tendencia al agrupamiento; Los ítems tienden a agruparse en la tabla. Esto significa que si se producen muchas colisiones con el mismo valor hash, se llenará cierto número de ranuras circundantes debido a la solución mediante prueba lineal. Esto tendrá un impacto en otros ítems que estén siendo insertados, como vimos antes cuando tratamos de agregar el ítem 20. Un grupo de ítems con valor hash 0 tendrían que ser saltados para finalmente encontrar una posición disponible. Este grupo se muestra en la Figura 9.

Figura 9: Un grupo de ítems para la ranura 0¶
Figura 9: Un grupo de ítems para la ranura 0
Una manera de lidiar con el agrupamiento es extender la técnica de prueba lineal de modo que en vez de buscar secuencialmente la siguiente ranura disponible, saltemos ranuras, distribuyendo de manera más uniforme los ítems que han causado colisiones. Esto potencialmente reducirá el agrupamiento que se produce. La Figura 10 muestra los ítems cuando la solución de colisiones se realiza con una prueba “más 3”. Esto significa que una vez se produzca una colisión, examinaremos cada tercera ranura hasta encontrar una que esté vacía.

Figura 10: Solución de colisiones usando “Más 3”¶
Figura 10: Solución de colisiones usando “Más 3”
El nombre general para este proceso de buscar otra ranura después de una colisión es transformación de claves repetida (rehashing). Con prueba lineal simple, la función rehash es \(valorHashNuevo = rehash(valorHashViejo)\) donde \(rehash(pos) = (pos + 1) \% tamanoDeTabla\). El rehash “más 3” se puede definir como \(rehash(pos) = (pos + 3) \% tamanoDeTabla\). En general \(rehash(pos) = (pos + salto) \% tamanoDeTabla\). Es importante tener en cuenta que el tamaño del “salto” debe ser tal que todas las ranuras en la tabla eventualmente sean visitadas. De lo contrario, parte de la tabla no se utilizará. Para asegurar esto, a menudo se sugiere que el tamaño de la tabla sea un número primo. Ésa es la razón por la que en nuestros ejemplos hemos estado usando 11.
Una variación de la idea de la prueba lineal se denomina prueba cuadrática. En lugar de usar un valor de “salto” constante, usamos una función rehash que incrementa el valor de hash en 1, 4, 9, 16, etc. Esto significa que si el primer valor hash es h, los valores sucesivos son \(h+1\), \(h+4\), \(h+9\), \(h+16\), y así sucesivamente. En otras palabras, la prueba cuadrática utiliza un salto que consiste en cuadrados perfectos sucesivos. La Figura 11 muestra nuestros valores de ejemplo después de que son ubicados utilizando esta técnica.

Figura 11: Solución de colisiones usando prueba cuadrática¶
Figura 11: Solución de colisiones usando prueba cuadrática
Un método alternativo para manejar el problema de colisiones es permitir que cada ranura contenga una referencia a una colección (o cadena) de ítems. El encadenamiento permite que muchos ítems existan en la misma ubicación en la tabla hash. Cuando ocurren colisiones, el elemento todavía se coloca en la ranura adecuada de la tabla hash. A medida que más y más ítems obtienen un valor hash a la misma ubicación, aumenta la dificultad de buscar el ítem en la colección. La Figura 12 muestra los ítems a medida que se agregan a una tabla hash que utiliza encadenamiento para resolver las colisiones.
Figura 12: Solución de colisiones con encadenamiento¶
Figura 12: Solución de colisiones con encadenamiento
Cuando queremos buscar un ítem, usamos la función hash para generar la ranura donde debe residir. Puesto que cada ranura contiene una colección, utilizamos una técnica de búsqueda para decidir si el elemento está presente. La ventaja es que en promedio es probable que haya muchos menos ítems en cada ranura, así que la búsqueda es quizás más eficiente. Examinaremos el análisis de la transformación de claves al final de esta sección.
Autoevaluación
- 1, 10
- Tenga cuidado en usar el residuo, no la división entera
- 13, 0
- No divida entre dos, use el operador módulo.
- 1, 0
- 27 % 13 == 1 y 130 % 13 == 0
- 2, 3
- Use el operador módulo
Q-1: En una tabla hash de tamaño 13, ¿qué índices de posición corresponden a las siguientes dos claves?: 27, 130
- 100, __, __, 113, 114, 105, 116, 117, 97, 108, 99
- Parece que usted puede haber estado aplicando aritmética módulo 2. Usted necesita utilizar el tamaño de la tabla hash como valor de la operación módulo.
- 99, 100, __, 113, 114, __, 116, 117, 105, 97, 108
- El uso de aritmética módulo 11 y de prueba lineal da estos valores
- 100, 113, 117, 97, 14, 108, 116, 105, 99, __, __
- Parece que usted puede haber estado aplicando aritmética módulo 10, use el tamaño de la tabla.
- 117, 114, 108, 116, 105, 99, __, __, 97, 100, 113
- Tenga cuidado en usar la operación módulo, no la división entera
Q-2: Supongamos que a usted se le da el siguiente conjunto de claves para insertar en una tabla hash que puede contener exactamente 11 valores: 113, 117, 97, 100, 114, 108, 116, 105, 99 ¿Cuál de las siguientes opciones demuestra mejor el contenido de la tabla hash después de que se han insertado todas las claves utilizando la prueba lineal?
5.5.3. Implementación del tipo abstracto de datos Vector Asociativo¶
Una de las colecciones más útiles de Python es el diccionario. Recuerde que un diccionario es un tipo de datos asociativo donde usted puede almacenar parejas clave-valor. La clave se utiliza para buscar el valor de datos asociado. A menudo nos referimos a esta idea como un vector asociativo o mapa.
El tipo abstracto de datos Vector Asociativo se define como sigue. La estructura es una colección no ordenada de asociaciones entre una clave y un valor de datos. Las claves de un vector asociativo son únicas para que exista una relación uno a uno entre una clave y un valor. Las operaciones se dan a continuación.
VectorAsociativo()Crea un vector asociativo nuevo y vacío. Devuelve una colección vector asociativo vacía.agregar(clave,valor)Agrega una nueva pareja clave-valor al vector asociativo. Si la clave ya está en el vector asociativo, reemplaza el valor anterior por el nuevo.obtener(clave)Dada una clave, devuelva el valor almacenado en el vector asociativo oNonede lo contrario.eliminarElimina la pareja clave-valor del vector asociativo utilizando una instrucción de la formaeliminar VectorAsociativo[clave].tamano()Devuelve el número de parejas clave-valor almacenadas en el vector asociativo.inDevuelveTruepara una instrucción de la formaclave in VectorAsociativo, si la clave dada está en el vector asociativo,Falsede lo contrario.
Uno de los grandes beneficios de un diccionario es el hecho de que dada una clave, podemos buscar el valor del dato asociado muy rápidamente. Con el fin de proporcionar esta capacidad de búsqueda rápida, necesitamos una implementación que soporte una búsqueda eficiente. Podríamos usar una lista con búsqueda secuencial o binaria, pero sería incluso mejor usar una tabla hash como se ha descrito anteriormente, ya que la búsqueda de un ítem en una tabla hash se acerca a un desempeño \(O(1)\).
En el Programa 2 utilizamos dos listas para crear una clase TablaHash que implementa el tipo abstracto de datos Vector Asociativo. Una lista, llamada ranuras, contendrá los ítems que constituyen las claves y una lista paralela, llamada datos, almacenará los valores de los datos. Cuando busquemos una clave, la posición correspondiente en la lista de datos contendrá el valor de datos asociado a la clave. Trataremos la lista de claves como una tabla hash utilizando las ideas presentadas anteriormente. Tenga en cuenta que el tamaño inicial de la tabla hash se ha elegido que sea 11. Aunque esto es arbitrario, es importante que el tamaño sea un número primo para que el algoritmo de solución de colisión pueda ser lo más eficiente posible.
Programa 2
class TablaHash:
def __init__(self):
self.tamano = 11
self.ranuras = [None] * self.tamano
self.datos = [None] * self.tamano
La función funcionHash implementa el método simple del residuo. La técnica de solución de colisiones es la prueba lineal con una función rehash “más 1”. La función agregar (ver el Programa 3) asume que habrá una ranura vacía a menos que la clave ya esté presente en self.ranuras. Dicha función calcula el valor hash original y si esa ranura no está vacía, repite la función rehash hasta que aparezca una ranura vacía. Si una ranura no vacía ya contiene la clave, el valor del dato antiguo se reemplaza con el nuevo valor del dato. Hacer frente a la situación en la que no quedan ranuras vacías se deja como un ejercicio.
Programa 3
def agregar(self,clave,dato):
valorHash = self.funcionHash(clave,len(self.ranuras))
if self.ranuras[valorHash] == None:
self.ranuras[valorHash] = clave
self.datos[valorHash] = dato
else:
if self.ranuras[valorHash] == clave:
self.datos[valorHash] = dato #reemplazo
else:
proximaRanura = self.rehash(valorHash,len(self.ranuras))
while self.ranuras[proximaRanura] != None and \
self.ranuras[proximaRanura] != clave:
proximaRanura = self.rehash(proximaRanura,len(self.ranuras))
if self.ranuras[proximaRanura] == None:
self.ranuras[proximaRanura]=clave
self.datos[proximaRanura]=dato
else:
self.datos[proximaRanura] = dato #reemplazo
def funcionHash(self,clave,tamano):
return clave%tamano
def rehash(self,hashViejo,tamano):
return (hashViejo+1)%tamano
Del mismo modo, la función obtener (ver Programa 4) comienza calculando el valor hash inicial. Si el valor no está en la ranura inicial, se usa la función rehash para localizar la siguiente posición posible. Observe que la línea 15 garantiza que la búsqueda finalizará comprobando que no hemos regresado a la ranura inicial. Si eso ocurre, hemos agotado todas las ranuras posibles y el ítem no debe estar presente.
Los métodos finales de la clase TablaHash proporcionan funcionalidad adicional de diccionarios. Sobrecargamos los métodos __getitem__ y __setitem__ para permitir el acceso usando []. Esto significa que una vez se ha creado una TablaHash, el familiar operador de índización estará disponible. Dejamos los métodos restantes como ejercicios.
Programa 4
1def obtener(self,clave):
2 ranuraInicio = self.funcionHash(clave,len(self.ranuras))
3
4 dato = None
5 parar = False
6 encontrado = False
7 posicion = ranuraInicio
8 while self.ranuras[posicion] != None and \
9 not encontrado and not parar:
10 if self.ranuras[posicion] == clave:
11 encontrado = True
12 dato = self.datos[posicion]
13 else:
14 posicion=self.rehash(posicion,len(self.ranuras))
15 if posicion == ranuraInicio:
16 parar = True
17 return dato
18
19def __getitem__(self,clave):
20 return self.obtener(clave)
21
22def __setitem__(self,clave,dato):
23 self.agregar(clave,dato)
La siguiente sesión muestra la clase TablaHash en acción. En primer lugar vamos a crear una tabla hash y a almacenar algunos ítems con claves enteras y valores de datos que sean cadenas de caracteres.
>>> H=TablaHash()
>>> H[54]="gato"
>>> H[26]="perro"
>>> H[93]="leon"
>>> H[17]="tigre"
>>> H[77]="pajaro"
>>> H[31]="vaca"
>>> H[44]="cabra"
>>> H[55]="cerdo"
>>> H[20]="pollo"
>>> H.ranuras
[77, 44, 55, 20, 26, 93, 17, None, None, 31, 54]
>>> H.datos
['pajaro', 'cabra', 'cerdo', 'pollo', 'perro',
'leon', 'tigre', None, None, 'vaca', 'gato']
A continuación, accederemos y modificaremos algunos ítems de la tabla hash. Observe que el valor para la clave 20 está siendo reemplazando.
>>> H[20]
'pollo'
>>> H[17]
'tigre'
>>> H[20]='pato'
>>> H[20]
'pato'
>>> H.datos
['pajaro', 'cabra', 'cerdo', 'pato', 'perro',
'leon', 'tigre', None, None, 'vaca', 'gato']
>> print(H[99])
None
El ejemplo completo de la tabla hash se encuentra en el ActiveCode 1.
5.5.4. Análisis de la transformación de claves¶
Hemos dicho anteriormente que, en el mejor caso, la transformación de claves brindaría una técnica de búsqueda de tiempo constante \(O(1)\). Sin embargo, debido a las colisiones, el número de comparaciones no suele ser tan simple. A pesar de que un análisis completo de la transformación de claves está más allá del alcance de este texto, podemos indicar algunos resultados bien conocidos que aproximan el número de comparaciones necesarias para buscar un ítem.
La información más importante que necesitamos para analizar el uso de una tabla hash es el factor de carga, \(\lambda\). Conceptualmente, si \(\lambda\) es pequeño, entonces hay una menor probabilidad de colisiones, lo que significa que los elementos tienen más probabilidades de estar en las ranuras donde pertenecen. Si \(\lambda\) es grande, lo que significa que la tabla se está llenando, entonces hay más y más colisiones. Esto significa que la solución de colisiones es más difícil, requiriendo más comparaciones para encontrar una ranura vacía. Con el encadenamiento, un incremento en las colisiones significa un incremento en el número de ítems en cada cadena.
Como antes, tendremos un resultado tanto para una búsqueda exitosa como para una búsqueda sin éxito. Para una búsqueda exitosa usando direccionamiento abierto con prueba lineal, el número promedio de comparaciones es aproximadamente \(\frac{1}{2}\left(1+\frac{1}{1-\lambda}\right)\) y para una búsqueda infructuosa es \(\frac{1}{2}\left(1+\left(\frac{1}{1-\lambda}\right)^2\right)\). Si estamos utilizando encadenamiento, el número promedio de comparaciones es \(1 + \frac {\lambda}{2}\) para el caso exitoso, y simplemente \(\lambda\) comparaciones si la búsqueda no tiene éxito.