
5.4. La búsqueda binaria¶
Es posible aprovechar mejor la lista ordenada si somos inteligentes en nuestras comparaciones. En la búsqueda secuencial, cuando comparamos contra el primer ítem, hay a lo sumo \(n-1\) ítems restantes para verificar si el primer ítem no es el valor que estamos buscando. En lugar de buscar secuencialmente en la lista, una búsqueda binaria comenzará examinando el ítem central. Si ese ítem es el que estamos buscando, hemos terminado. Si no es el ítem correcto, podemos utilizar la naturaleza ordenada de la lista para eliminar la mitad de los ítems restantes. Si el ítem que buscamos es mayor que el ítem central, sabemos que toda la mitad inferior de la lista, así como el ítem central, se pueden ignorar de la consideración posterior. El ítem, si es que está en la lista, debe estar en la mitad superior.
Podemos entonces repetir el proceso con la mitad superior. Comenzar en el ítem central y compararlo con el valor que estamos buscando. Una vez más, o lo encontramos o dividimos la lista por la mitad, eliminando por tanto otra gran parte de nuestro espacio de búsqueda posible. La Figura 3 muestra cómo este algoritmo puede encontrar rápidamente el valor 54. La función completa se muestra en el CodeLens 3.
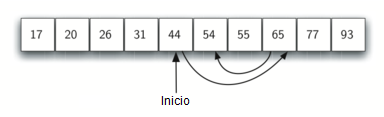
Figura 3: Búsqueda binaria en una lista ordenada de enteros¶
Figura 3: Búsqueda binaria en una lista ordenada de enteros
Activity: CodeLens Búsqueda binaria en una lista ordenada (search3)
Antes de pasar al análisis, debemos observar que este algoritmo es un gran ejemplo de una estrategia de dividir y conquistar. Dividir y conquistar significa que dividimos el problema en partes más pequeñas, resolvemos dichas partes más pequeñas de alguna manera y luego reensamblamos todo el problema para obtener el resultado. Cuando realizamos una búsqueda binaria en una lista, primero verificamos el ítem central. Si el ítem que estamos buscando es menor que el ítem central, podemos simplemente realizar una búsqueda binaria en la mitad izquierda de la lista original. Del mismo modo, si el ítem es mayor, podemos realizar una búsqueda binaria en la mitad derecha. De cualquier manera, ésta es una llamada recursiva a la función de búsqueda binaria pasándole una lista más pequeña. El CodeLens 4 muestra esta versión recursiva.
Activity: CodeLens Una búsqueda binaria--Versión recursiva (search4)
5.4.1. Análisis de la búsqueda binaria¶
Para analizar el algoritmo de búsqueda binaria, necesitamos recordar que cada comparación elimina aproximadamente la mitad de los ítem restantes de la consideración. ¿Cuál es el número máximo de comparaciones que este algoritmo requerirá para examinar la lista completa? Si empezamos con n ítems, alrededor de \(\frac{n}{2}\) ítems se dejarán después de la primera comparación. Después de la segunda comparación, habrá aproximadamente \(\frac{n}{4}\). Después \(\frac{n}{8}\), \(\frac{n}{16}\), y así sucesivamente. ¿Cuántas veces podemos dividir la lista? La Tabla 3 nos ayuda a ver la respuesta.
Comparaciones |
Número aproximado de ítems restantes |
|---|---|
1 |
\(\frac {n}{2}\) |
2 |
\(\frac {n}{4}\) |
3 |
\(\frac {n}{8}\) |
… |
|
i |
\(\frac {n}{2^i}\) |
Cuando dividimos la lista suficientes veces, terminamos con una lista que tiene un único ítem. Ya sea aquél ítem único el valor que estamos buscando o no lo sea. En todo caso, habremos terminado. El número de comparaciones necesarias para llegar a este punto es i donde \(\frac {n}{2^i} = 1\). La solución para i nos da \(i=\log n\). El número máximo de comparaciones es logarítmico con respecto al número de ítems de la lista. Por lo tanto, la búsqueda binaria es \(O(\log n)\).
Es necesario enfrentar una cuestión de análisis adicional. En la solución recursiva mostrada anteriormente, la llamada recursiva,
busquedaBinaria(unaLista[:puntoMedio],item)
usa el operador de partición para crear la mitad izquierda de la lista que se pasa a la siguiente invocación (similarmente para la mitad derecha también). En el análisis que hicimos arriba se asumió que el operador de partición requiere un tiempo constante. Sin embargo, sabemos que el operador de partición en Python es realmente O(k). Esto significa que la búsqueda binaria utilizando la partición no funcionará estrictamente en tiempo logarítmico. Por suerte esto se puede remediar pasando la lista junto con los índices de inicio y final. Los índices se pueden calcular como lo hicimos en el Programa 3. Dejamos esta implementación como ejercicio.
A pesar de que una búsqueda binaria es generalmente mejor que una búsqueda secuencial, es importante tener en cuenta que para valores pequeños de n, el costo adicional del ordenamiento probablemente no vale la pena. De hecho, siempre debemos considerar si es rentable asumir el trabajo extra del ordenamiento para obtener beneficios en la búsqueda. Si podemos ordenar una sola vez y luego buscar muchas veces, el costo del ordenamiento no es tan significativo. Sin embargo, para listas grandes, incluso ordenar una vez puede resultar tan costoso que simplemente realizar una búsqueda secuencial desde el principio podría ser la mejor opción.
Autoevaluación
- 11, 5, 6, 8
- Parece que usted podría haber errado por un paso. Recuerde que la primera posición es el índice 0.
- 12, 6, 11, 8
- La búsqueda binaria comienza en el punto medio y cada vez divide la lista por la mitad.
- 3, 5, 6, 8
- La búsqueda binaria no comienza al principio y busca secuencialmente, ella comienza en el centro y parte la lista por la mitad después de cada comparación.
- 18, 12, 6, 8
- Parece que usted est´ comenzando desde el final y está partiendo cada vez la lista a la mitad.
Q-3: Suponga que usted tiene la siguiente lista ordenada [3, 5, 6, 8, 11, 12, 14, 15, 17, 18] y que está utilizando el algoritmo de búsqueda binaria recursiva. ¿Qué grupo de numeros muestra correctamente la secuencia de comparaciones utilizadas para encontrar la clave 8?
- 11, 14, 17
- Parece que usted podría haber errado por un paso. Recuerde que la primera posición es el índice 0.
- 18, 17, 15
- Recuerde que la búsqueda binaria comienza en la mitad y divide la lista en dos partes.
- 14, 17, 15
- Parece que usted podría haber errado por un paso, tenga cuidado de que esté calculando el punto medio utilizando aritmética de enteros.
- 12, 17, 15
- La búsqueda binaria comienza en el punto medio y cada vez divide la lista por la mitad. La búsqueda termina cuando la lista est´ vacía.
Q-4: Suponga que usted tiene la siguiente lista ordenada [3, 5, 6, 8, 11, 12, 14, 15, 17, 18] y está utilizando el algoritmo de búsqueda binaria recursiva. ¿Qué grupo de números muestra correctamente la secuencia de comparaciones utilizadas para buscar la clave 16?