
2.3. Case Study 1: Adding More Happiness Data¶
2.3.1. Happiness by Region¶
Let’s create a table displaying the average happiness score for all of the countries in the region. To get started, we need to answer a couple of questions.
What are the unique region names?
How can we compute an average for the countries that are in the same region?
We can get a table of the unique region names by using the
UNIQUEfunction. In cell A180, theUNIQUEfunction takes the range that contains all of the region names, and will populate a few rows with just the unique names.Now, let’s make that list of countries look a little nicer by sorting it. Select the countries and then from the menu select Data -> Sort sheet by. Then select ascending order(A->Z).
You should have noticed an issue. The problem is that
UNIQUEis a special kind of function that returns an array of values. We need to make the values in the columns permanent before we sort them. To do this, we can select the names again, then copy them to the clipboard. Now, immediately choose Edit -> Paste Special -> Paste values only, and this will eliminate the formula and leave us with cells containing only the names of the regions.With the table of Regions, we can use a combination of
SUMIFandCOUNTIFto compute the average happiness. Let’s do this incrementally to start. Let’s create a column right next to the region names that contains the number of countries in the region. TheCOUNTIFfunction takes a range of cells and a condition for those cells to match. In our case, the range is B2:B141, that is, all of the regions. The condition is the name of the region which we can get from a cell in our newly created table of region names.
Now, let’s create a column that sums the happiness score for each region using
the SUMIF function. The SUMIF function is a bit more complicated than
COUNTIF in that it takes a separate (parallel) range for us to sum. Once again,
the first parameter will be the range containing the regions, the second
parameter will be the name of a region to match. In this case, there is a third
parameter that is the range of cells containing the happiness scores. When a row
in the Region column matches the given Region, the function includes the value
from the Happiness score column in the sum.
With a column for the count and a column for the sum, you can now calculate the mean by dividing our two columns.
We can combine the work we did above using a single function called
AVERAGEIF. Let’s use it and compare our answers. (They should be identical.) By now, you should be feeling some respect for the spreadsheet jockeys of the world. This is definitely not a toy!Last but not least, let’s sort the happiness scores so we can see the regions from most to least happy.
Select the table and then from the Data menu select Sort Range, choose column B and check the box for Z->A then sort.
North America and ANZ (Australia / New Zealand) are the happiest (Aussie Aussie Aussie) and Sub-Saharan Africa is the least happy.
Add another column to our table that tells us how many countries are in each region (
COUNTIF).Using
MAXIFS,MINIFS,MATCH, andINDEX, let’s find the most and least happy country in each region.MAXIFSandMINIFSwork likeAVERAGEIFandCOUNTIF, but allow for more conditions. In our case, we still need only one. (If you read the popup you will know what to do.)
2.3.2. Joining Data from Other Sources¶
So far, we have limited our analysis to the data provided for us in the original happiness spreadsheet. But what if we wanted to look at other factors for happiness, such as cell phone ownership, internet access, birth rates, or anything else we can think of? Seldom does one file contain all the data you need to answer the questions you may have. In this part of the project, we will import a spreadsheet that has a lot more data about each country, including its continent (see question 5). This is an important lesson as it sets the stage nicely for what we will learn about later when using SQL to “join” two tables of data.
The first thing we need to do is to import the countries of the world spreadsheet. This has a huge amount of data about each country and you may wish to explore some of the other data provided later. For now, we are interested in how we can use the information on this new spreadsheet to give us the continent of each country.
You can start by either copy/pasting the whole sheet into a new tab or importing the csv file into a new tab.
Next, we will want to add a column to the happiness spreadsheet that contains the population for each country. The way we do this is to use the
VLOOKUPfunction. Pay attention to this as it is one of the most powerful functions you will learn about. The main idea behind this is also widely used in the database world, so it is worth learning in detail.
The idea goes like this. On our happiness spreadsheet, we have a column that contains the name of each country. It has a bunch of happiness related data about each country in other columns. On our countries of the world sheet, we have a column of country names and a bunch of other information about countries (including their population) in other columns. The two sheets do not have the countries in the same order, nor do they necessarily have the same list of countries. (They do have most of the same but not all.)
When we use VLOOKUP, our goal is to join together these two sheets, adding
columns to the happiness sheet using values from the row in the countries of the
world sheet from the row where the country names match. For example, in our
happiness sheet, Ireland is on row 15, but in the countries of the world sheet,
it is on row 101. What we want to do is take (at least) column B row 101 from
the countries sheet, and add it to the happiness sheet on row 15 column M.
With VLOOKUP, we do this by allowing the function to search for the value in
one cell in another column, and then return the value from a different cell in
the same row but in some other column. To find the continent of Ireland, we would
use VLOOKUP(A15, Sheet1!$A$6:$F$229, 5, FALSE).
A15 is the cell containing Ireland
Sheet1!$A$6:$F$229is the range of cells we can search in as well as get values from5 tells Sheets that when we find a match for Ireland, we want the value from the same row but in column 5 of our range
Notice that column 5 of our range is the continent/region column. You may have
noticed that VLOOKUP is a bit like using MATCH and INDEX together,
but it is a little less flexible, as the column you search in must always be on
the far left side of the range.
To add a whole new column to fill in the region for each country, we would type
the following into O2: =VLOOKUP(A2, Sheet1!$A$6:$F$229, 5, FALSE). Now if
you double-click on the blue square in the lower right corner when you have M2
selected, you will see that Sheets will automatically copy/paste the formula
down the column. It will do this until it finds a blank cell to the left, then
it will stop. If your spreadsheet has some missing data, this can lead to some
unexpected results, so it’s always a good idea to make sure it has pasted all
the way down.
As you found out, there are some rows that have a value of #N/A in them. This is because one spreadsheet has the name “United States” and the other spreadsheet has “United States of America”. We know these are the same but the computer does not make the match. You will need to clean up this data manually by making the names match where they don’t already. This is also why the countries of the world spreadsheet contains the column that has a three-letter code for each country. These codes are internationally agreed upon and are always the same for each country. This avoids the kind of problems we have where there is more than one common spelling.
Any time you are introducing data from another source, you are likely to run into inconsistencies and missing data. That is just a simple fact of life for a data scientist. You will need to either search further to fill in the missing pieces, or learn to live without some pieces of data.
Kosovo
-
Correct
Palestine
-
Correct
Palau
-
No, Palau is there
Ivory Coast
-
Technically this one is there but you need to make it “Côte d’Ivoire”
Q-7: Which of the following countries are NOT in the world countries spreadsheet?
Now that you have country names unified and the population data in place, you can practice some calculations on this new piece of data.
Calculate the average population for each region?
Find the name of the country in each region with the largest population.
What is the country in each region with the smallest population?
Q-11: Write down two questions of your own, that you can explore with the combined data set.
Now, using your new spreadsheet skills answer your own questions.
Q-12: Use this space to provide answers to the questions above, explaining briefly how you arrived at the answers.
2.3.3. Introducing Pivot Tables¶
We can make all of this a bit easier using a pivot table! This is a really useful tool to have in your toolbox, and many other tools you use will support the creation of pivot tables as well.
The idea behind a pivot table is to take the unique values from some column and make them the titles of a bunch of columns, while summarizing the data for those columns from a number of rows. For example, suppose you had a table with three columns: user, movie, and rating. What would be more easy to look at would be to have a column for each movie and a row for each user with the rating in the cell corresponding to a user and a movie. This is exactly the use case for pivot tables. You can see an example of transforming the original data to the pivot table view below.
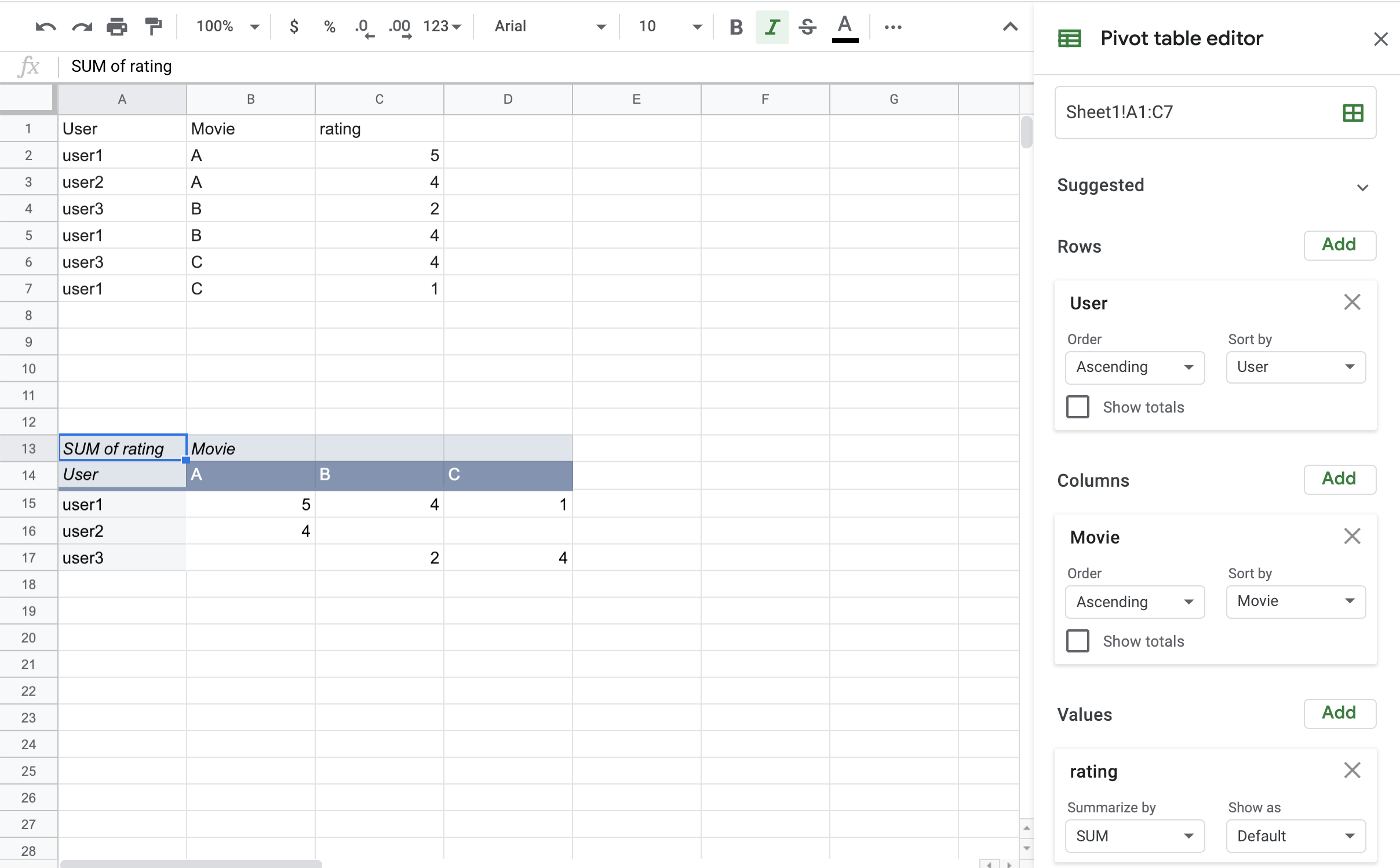
Start a new worksheet, and recreate the data and pivot table you see in the example above.
Another good use case is to replace what we have just done. We want to use the unique values for each continent as the row, and then calculate a number of summary statistics for each. For practice, you should redo the exercise of finding the average population for each region that you did above.
Pivot tables can be treated like any other part of your spreadsheet. Use a pivot
table to find the least happy country in each region. Then using MATCH and
INDEX, add an additional column that contains the name of that country.
You will find that understanding Pivot tables and knowing when to use them to be a very powerful tool to have in your toolbox. Many other systems, including Pandas and relational databases like PostgreSQL, also support making pivot tables. The interface in Sheets is the simplest, so it is a good system to learn on.
Lesson Feedback
-
During this lesson I was primarily in my...
- 1. Comfort Zone
- 2. Learning Zone
- 3. Panic Zone
-
Completing this lesson took...
- 1. Very little time
- 2. A reasonable amount of time
- 3. More time than is reasonable
-
Based on my own interests and needs, the things taught in this lesson...
- 1. Don't seem worth learning
- 2. May be worth learning
- 3. Are definitely worth learning
-
For me to master the things taught in this lesson feels...
- 1. Definitely within reach
- 2. Within reach if I try my hardest
- 3. Out of reach no matter how hard I try