
9.14. Predicting Daily Bike Rentals¶
Let’s say you are a new data scientist working for Bikes-R-Us. Your boss comes to you and asks you to develop a model for predicting bike rentals in the future. The company is trying to decide whether to invest in more bikes so they can keep stations better stocked. It is early in 2013, and what you have to work with is a database of rental information similar to the one with which we began this chapter. The difference is that we have two full years of data (2011 and 2012) to work with. Because 2010 was a partial and startup year, that data has been discounted as too unreliable. You can get this data from the bikeshare_11_12.db file.
You probably have several questions here.
How do you start?
How will you know if you are even on the right track to building a good model?
What data can you use as features when you build the model?
Should you be trying to predict rentals by hour, by day, by month?
With big problems like this, it’s easy to get overwhelmed with the scope of the problem. It’s also easy to want to make something really complex right away. A better approach is to try something simple at first (Keep It Simple Stupid, or KISS). If a simple solution works, why spend additional time and effort to make something complicated?
Your initial thought is that you can build a model using the date as the main feature. You know that the database contains the information to calculate the total number of bikes rented each day. That seems like a simple approach, but how are you going to know, much less convince your boss, that your model is any good? You don’t know what bike rentals are going to be in the future, and that is what you are supposed to predict. Showing your boss the mean squared error is not likely to be too convincing, as you are just confirming the data that you have used to build the model.
This is where the train-test split comes in handy. It lets you use your existing data to prove that your model works!
9.14.1. The Train-Test Split¶
The way to handle the problem of quantifying the quality of your model is to hold out some of the data that you already have. Let’s take 20% of the days that we have data for, and NOT use them in building the model. Then we can make predictions for those days and check our work. It’s kind of like covering up the answer to a math problem so you don’t cheat and just look at the answer. We call this a train-test split. We will randomly select some data to include in building the model, and some data to leave out. Scikit-learn even has a handy utility function that will do this for us!
To be a little more scientific about this, we will split our data into a “training set” that we will use to build the model, and a “test set” that we will use to validate the model. That is, we want to test our model on data that is different from the data we used to build the model. Testing using the data that you trained on would be like cheating, as you could just build a model that memorized everything and got 100%. In the real world, you need to make predictions for things that you have not seen before.
The first thing we’ll do is create two simplified DataFrames: one that contains
a column containing the date, and one that contains a column of the number of
bikes rented on that date. Next, we’ll randomly select 80% of the data to use in
creating our linear regression model. This leaves 20% of the data to use in
testing. We will use the scikit-learn train_test_split function, which
returns the following DataFrames.
train_X,train_y: This is the data we’ll use to create our model. Remember that in linear regression we are trying to come up with a slope and intercept value that minimize the error, so we need to know the answer.test_X: We will use this data (withouttrain_y) to make predictions, given a rating fromtest_Xto calculate a predicted overall value.test_y: We will use this data along with the predicted values to come up with our score. The score we calculate will be the mean absolute error.
By default the
train_test_split
function takes parameters as follows:
train_test_split(features_df, answer_df, test_size, random_state).
The train_test_split function contains an optional parameter called
random_state. We will use random_state=997 for this parameter to ensure
we are all getting the same randomness. This will allow you to compare your
results against mine and your classmates’. It will also make your results
reproducible from one day to the next.
Let’s try this:
import pandas as pd
from sklearn.model_selection import train_test_split
trips = pd.read_csv("https://runestone.academy/ns/books/published/httlads/_static/trip_data.csv",
parse_dates=['start_date','end_date'])
Now let’s make start date the index, resample, and count the number of trips on each day.
trips = trips.set_index('start_date')
trips = trips.resample('D').count()
trips = trips[['duration']]
trips.columns=['trip_count']
trips = trips.reset_index()
trips.head()
| start_date | trip_count | |
|---|---|---|
| 0 | 2011-01-01 | 959 |
| 1 | 2011-01-02 | 781 |
| 2 | 2011-01-03 | 1301 |
| 3 | 2011-01-04 | 1536 |
| 4 | 2011-01-05 | 1571 |
Now we have a simple data frame, the feature is the date and the thing we want to predict is the number of rides on each day
X_train, X_test, y_train, y_test = train_test_split(trips.start_date, trips.trip_count, test_size=0.20, random_state=997)
print(X_train)
print(y_train)
703 2012-12-04
475 2012-04-20
164 2011-06-14
261 2011-09-19
548 2012-07-02
...
205 2011-07-25
485 2012-04-30
638 2012-09-30
454 2012-03-30
628 2012-09-20
Name: start_date, Length: 584, dtype: datetime64[us]
703 6562
475 7203
164 4829
261 4467
548 6158
...
205 3790
485 5528
638 6812
454 5411
628 7659
Name: trip_count, Length: 584, dtype: int64
Notice that when we print the values for X_train and y_train that the index values match row by row. The next step is to train our model using the X_train and y_train data. Then we can come back and try to use the model to make predictions using the X_test data. Having the y_test data in hand will allow us to evaluate the model.
9.14.2. Evaluating the Model¶
Now that we have the train-test split, we can use the mean squared error on the difference between our predicted values for the test data and the known values for the test data. This is a much fairer model evaluation as we are not using any of the data that the model already “knowns” the answer for. In addition to the mean squared error, we can also compute the mean absolute error. This is a little nicer for us because the units of the error are the same as what we are trying to predict. In this case, we are not trying to predict bike rentals squared (whatever that means), but simply the number of bike rentals. We can also compute a measure called \(R^2\) which is a measure of how close the data are to the regression line.
9.14.3. Feature Engineering¶
Up to this point, we’ve been making an assumption that a date is something we
can just send into the LinearRegression model and it will all work.
Unfortunately, that is not the case. The LinearRegression model needs to
have the features represented as numbers. In the spirit of keeping it simple,
let’s build our first model by simply numbering each day using 0 as the first
day for which we have data, 1 for the second day, and so on up to whatever
number represents the last day.
9.14.4. Version 1.0 Task List¶
Your task list for this project is as follows
Read in the rental data from the database.
Transform the data into daily rental counts by resampling by day.
Number each day from 0 to N. Hint: sorting on the index and then resetting the index is a good starting point.
Make the train test split of the data using the
train_test_splitfunction.Create a new
LinearRegressionmodel and fit the training data.Calculate the mean squared error and mean absolute error between the known rentals from the test data and the predicted values from the model.
Make a graph to compare the training and test data.
You can use this colab notebook PredictingBikeRentals to get started. You will need to save a copy of the notebook in order to work with it for the exercises below.
Compare your graph to this one after you have made it.
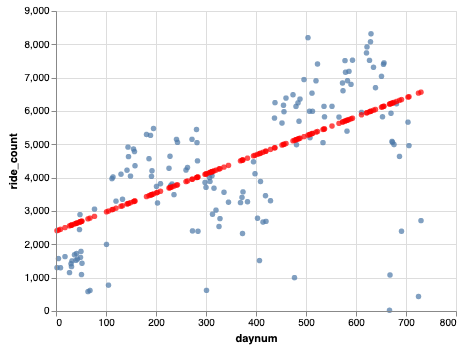
What do you think of the model so far? You are probably a bit disappointed, both with how the graph looks as well as the mean absolute error. Missing your daily predictions by over 900 is not great, especially in the earlier days when rentals were only around 1000. In fact, if the average daily rentals for this period is about 2750, then you are off by around 77% every day.
We can also look at the \(R^2\) score for this model, which is 0.373. 1.0 would be the best score possible, so we are a long way from there.
But what is the interpretation of \(R^2\)? It tells us how much of the variation of the data is explained by the model. Reviewing the graph from above, there is a lot of variation and our model is only accounting for 37% of it.
Let’s hold off on taking this model to the boss and see if we can refine our model to do a bit better.
9.14.5. Refining the Model¶
Don’t get discouraged that the first try wasn’t that great. You might have even guessed that that would be the case. (Textbook authors are mean that way.) Let’s look at the time series of daily rentals.
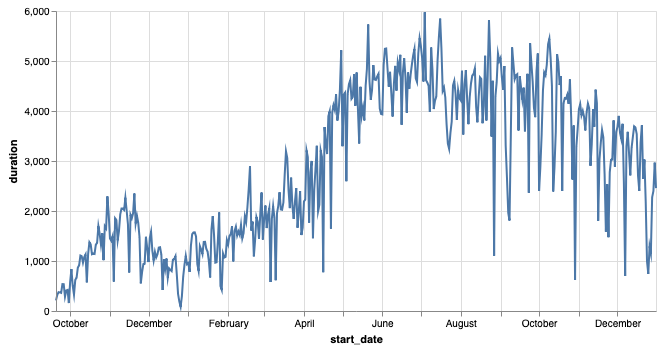
The representation of the date we chose is simple, but you know from the time series visualization, that numbering the days that way would leave out a lot of valuable information. You can see in the graph above that there are seasonal variations in the data as well as variations due to the day of the week. We also know that as we went from year to year, overall rentals kept growing. So, instead of encoding our date as a single number let’s encode the date by adding features for year, month, day and even weekday. Hopefully, by adding more features that capture the kinds of variation, we will help our model.
This kind of development of the model is very common. Start with a simple idea and then refine it, learning what you can from the previous refinements. Sometimes an idea you think will improve turns out to hurt more than it helps, so you have to abandon it. This is part of the joy and the frustration of data science: it is an experimental science. There is not necessarily one “right way” to get the best answer. In this particular example we might have to admit that we can only do so much. The shape of the time series is NOT a linear function, but we will do the best with the tools we have. The truth is that there are other approaches besides linear regression that will ultimately work better for data like this, but we can still learn a lot by trying to see how far we can push linear regression.
9.14.6. Version 2.0 Task List¶
Create four new features out of the date, a column for year, month, day, and weekday. We will keep daynum as a feature as well so that we can use it to build a graph. Later we can experiment to see if we need it at all.
Redo the train-test split using the same
random_stateas before.Fit a new model using the new features.
Make a new set of predictions for the test days.
Calculate the mean squared error, mean absolute error, and \(R^2\) for this new model against the known values.
Plot the predictions against daynum to see how they look with more features.
Let’s make one more refinement to our version 2.0 model. The problem with using month number in the hopes that we will capture seasonality is that it just doesn’t work. Numbering the months from 1 to 12 implies something linear about the months. So, although there is a linear relationship in that June comes after May on the calendar, for a problem where we care about seasonality, it doesn’t work. The winter months include 11, 12, 1, and 2. (Probably even 3 if you live in the Midwest.)
Let’s do a bit more feature engineering to see if we can make an improvement. Your first thought is probably to add a new column called season, however numbering the seasons winter=0, spring=1, summer=2, fall=3 is not really a solution, because there is not an ordered relationship between the seasons. Spring is not more than winter or better than winter, so assigning 0 to winter and 1 to spring is actually misleading. There are many examples of this, such as encoding gender, location information, or marital status. The general rule is that if the data is not ordinal, don’t encode it as ordinal! But how do we encode nominal data then to make use of it in our work? The solution to this in data science is to encode this information using a technique called one-hot encoding. To use one-hot encoding, we’ll add four new columns to our model, one for each season. If the date for a particular row of the model is in one of the winter months, then the value for winter will be 1 and the value for all other season columns will be 0. Similarly, if the date for a row corresponds to a date in the summer months, then the value for the summer column will be 1 and the value for all the other season columns will be 0. This allows us to capture the seasonal information and use it in our model.
9.14.7. Version 2.5 Task List¶
Update your DataFrame to do one-hot encoding for each of the seasons.
Retrain and retest your model.
Cool! That gave us some real improvement.
After you have made the graph yourself, take a look and see if your graph matches this one.
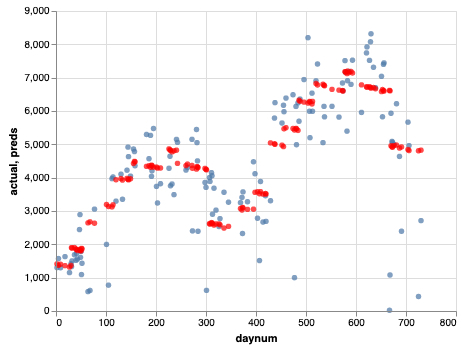
9.14.8. Version 3.0¶
Now that you have been through the cycle a couple of times, you are probably saying to yourself: “Hey, there are other factors to bike rental besides just the day of the week or the season!” And you are correct, it may be that the weather on a particular day is more important than what day of the week it is! Who wants to rent a bike and ride through Washington DC in the rain or snow?
So, let’s add some weather information. This could be a good chance to practice your WebAPI skills again, or even do some screen scraping from a source that allows it. But we also have some weather data for you in a table in the database.
The weather data can be found in the weather table and looks like this.
weathersit: Weather situation, integer column with the following meaning1: Clear, Few clouds, Partly cloudy, Partly cloudy
2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
temp_f: Temperature in degrees Fahrenheitfeelslike_f: The feels like temperature in Fahrenheithumidity: percent from 0 to 100windspeed: Wind speed in mph
Let’s look at a few rows.
| date | hour | weathersit | temp_f | feelslike_f | humidity | windspeed | |
|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 | 0 | 1 | 37.904 | 37.40252 | 81.0 | 0.0 |
| 1 | 2011-01-01 | 1 | 1 | 36.212 | 35.59676 | 80.0 | 0.0 |
| 2 | 2011-01-01 | 2 | 1 | 36.212 | 35.59676 | 80.0 | 0.0 |
| 3 | 2011-01-01 | 3 | 1 | 37.904 | 37.40252 | 75.0 | 0.0 |
| 4 | 2011-01-01 | 4 | 1 | 37.904 | 37.40252 | 75.0 | 0.0 |
Incorporate this weather data into your model as you see fit. Experiment a bit and see what you can figure out.
Q-8: What was the lowest MAE you were able to achieve? Which weather features improved your score the most?
9.14.9. Feature Engineering - Re-Scaling¶
One last bit of feature engineering you can try is to
re-scale
the values of your features so they are all on a common scale. One of the
problems with leaving all the features in their “normal” units is that it warps
the n-dimensional space in strange ways. Some axes are elongated with respect to
other axes. For example, think about the values for our one-hot encoded features
like the season or weekend. Those values are either 0 or 1. However, the
temperature values can range from -8 to a max of 102. If you just use those two
features, think of how the 2-dimensional graph of isweekday looks, compared
to temperature.
Now, why is this a problem? Remember that we are trying to minimize the sum of squared errors as we try to find the coefficients for each of our features. (Go back and review our work with pizzas if you have forgotten.) What that means is that we are calculating the distance between a known point in some n-dimensional space, and a predicted point in the same n-dimensional space. But if some axes are really elongated and others are really short, that introduces a bias that the algorithm has to overcome. Whereas if you re-scale the temperature to be on a scale from 0 to 1, then you have a nice space where all the features are on the same scales and the algorithm can do its job more efficiently. This may not be the most important factor for regression, but for other machine learning algorithms, it is critical!
One really common method for transforming the data is to use min-max scaling.
This will ensure that all of your values are between 0 and 1.
9.14.10. Where to go from here?¶
In the introduction to this textbook, we showed you this diagram. Take a look at it again here.

You can see that we have now learned something about every box on that diagram.
In this chapter, you learned how to build one of the most commonly used kinds of
models in data science: regression. But regression analysis is just the tip of
the iceberg. There are many other kinds of models to learn about. The good news
for you is that you have some knowledge of the scikit-learn API. The API is
consistent across many other kinds of models whether it is LinearRegression
or LogisticRegression or DecisionTrees or Perceptron, you use the
same methods: fit, predict, etc. to train and test the model!
The next step for you is to find a different data set (hopefully something that is interesting to you, for example predicting the scores of soccer games, predicting trends in fashion, identifying tumors in MRI images), to practice what you have learned in this chapter.