
2.6. Listas¶
Los diseñadores de Python tuvieron que elegir entre muchas opciones cuando implementaron la estructura de datos lista. Cada una de estas opciones podría tener un impacto en la velocidad de las operaciones con listas. Para ayudarse en la toma de la decisión correcta, examinaron las maneras en que la gente usaría más comúnmente la estructura de datos lista y optimizaron su implementación de una lista de modo que las operaciones más comunes fueran muy rápidas. Por supuesto, también trataron de hacer rápidas las operaciones menos comunes, pero cuando había que encontrar un punto medio, a menudo fue sacrificado el desempeño de una operación menos común en favor de la operación más común.
Dos operaciones comunes son la indización y la asignación a una posición indizada. Ambas operaciones toman la misma cantidad de tiempo sin importar cuán grande sea la lista. Cuando una operación como ésta es independiente del tamaño de la lista, se dice que es \(O(1)\).
Otra tarea de programación muy común es hacer crecer una lista. Hay dos maneras de crear una lista más larga. usted puede utilizar el método append o el operador de concatenación. El método append es \(O(1)\). Sin embargo, el operador de concatenación es \(O(k)\) donde \(k\) es el tamaño de la lista que está siendo concatenada. Es importante que usted sepa esto porque puede ayudarle a hacer sus propios programas más eficientes eligiendo la herramienta de trabajo adecuada.
Veamos cuatro maneras diferentes de generar una lista de n números comenzando con 0. Primero probaremos un ciclo for y crearemos la lista por concatenación, luego usaremos append en lugar de la concatenación . A continuación, trataremos de crear la lista utilizando comprensión de listas y finalmente, y tal vez de la forma más obvia, utilizando la función range envuelta por una llamada al constructor de la lista. El Programa 3 muestra el código para hacer nuestra lista de cuatro maneras diferentes.
Programa 3
def prueba1():
l = []
for i in range(1000):
l = l + [i]
def prueba2():
l = []
for i in range(1000):
l.append(i)
def prueba3():
l = [i for i in range(1000)]
def prueba4():
l = list(range(1000))
Para capturar el tiempo que tarda cada una de nuestras funciones en ejecutarse, utilizaremos el módulo timeit de Python. El módulo timeit está diseñado para permitir a los desarrolladores de Python realizar mediciones de tiempos entre plataformas ejecutando funciones en un entorno consistente y utilizando mecanismos de temporización que sean lo más similares posibles entre sistemas operativos.
Para usar timeit, usted crea un objeto Timer cuyos parámetros son dos instrucciones de Python. El primer parámetro es una instrucción de Python a la que usted desea medir el tiempo; el segundo parámetro es una instrucción que se ejecutará una sola vez para configurar la prueba. El módulo timeit calculará entonces cuánto tiempo tarda en ejecutarse la instrucción cierto número veces. Por defecto timeit intentará ejecutar la instrucción un millón de veces. Cuando lo haya hecho, devuelve el tiempo como un valor de punto flotante que representa el número total de segundos. No obstante, dado que la instrucción se ejecuta un millón de veces, el resultado se puede leer como el número de microsegundos que toma ejecutar la prueba una sola vez. Usted también puede pasar a timeit un parámetro llamado number que le permite especificar cuántas veces ejecutar la instrucción de prueba. La siguiente sesión muestra cuánto tiempo tarda en ejecutarse 1000 veces cada una de nuestras funciones de prueba.
t1 = Timer("prueba1()", "from __main__ import prueba1")
print("concatenación ",t1.timeit(number=1000), "milisegundos")
t2 = Timer("prueba2()", "from __main__ import prueba2")
print("append ",t2.timeit(number=1000), "milisegundos")
t3 = Timer("prueba3()", "from __main__ import prueba3")
print("comprensión ",t3.timeit(number=1000), "milisegundos")
t4 = Timer("prueba4()", "from __main__ import prueba4")
print("método range ",t4.timeit(number=1000), "milisegundos")
concatenación 6.54352807999 milisegundos
append 0.306292057037 milisegundos
comprensión 0.147661924362 milisegundos
método range 0.0655000209808 milisegundos
La instrucción a la que le estamos midiendo el tiempo en el experimento anterior es el llamado a prueba1(), prueba2(), y así sucesivamente. La instrucción de configuración puede parecer muy extraña para usted, así que vamos a considerarla con más detalle. Probablemente usted esté muy familiarizado con la instrucción from, import, pero usualmente se usa al principio de un archivo de programa de Python. En este caso la instrucción from __main__ import prueba1 importa la función prueba1 desde el espacio de nombres __main__ hacia el espacio de nombres que timeit establece para el experimento de medición de tiempos. El módulo timeit hace esto porque desea ejecutar las pruebas de medición de tiempo en un entorno que esté despejado de cualquier variable parásita que usted haya creado, que podría interferir con el desempeño de su función de alguna manera imprevista.
Del experimento anterior es claro que la operación append que tarda 0,30 milisegundos es mucho más rápida que la concatenación que tarda 6,54 milisegundos. En el experimento anterior también mostramos los tiempos de dos métodos adicionales para crear una lista: usar el constructor de lista con una llamada a range y una comprensión de listas. Es interesante observar que la comprensión de listas es dos veces más rápida que un ciclo for con una operación append.
Una última observación acerca de este pequeño experimento es que en todas las ocasiones que usted ve arriba se incluyó alguna sobrecarga para llamar realmente a la función de prueba, pero podemos suponer que la sobrecarga de la llamada a la función es idéntica en los cuatro casos, así que aún tenemos una comparación válida de las operaciones. Por lo tanto, no sería exacto decir que la operación de concatenación toma 6.54 milisegundos, sino que deberíamos decir que la función de prueba de la concatenación tarda 6.54 milisegundos. Como ejercicio, usted podría medir el tiempo que toma llamar a una función vacía y restarlo de los números anteriores.
Ahora que hemos visto cómo se puede medir el desempeño de forma concreta, fíjese en la Tabla 2 para ver la eficiencia O-grande de todas las operaciones básicas con listas. Después de examinar cuidadosamente la Tabla 2, es posible que usted se esté preguntando acerca de los dos tiempos diferentes para pop. Cuando pop es llamado sobre el final de la lista se tarda \(O(1)\) pero cuando pop es llamado sobre el primer elemento de la lista o en cualquier punto intermedio es \(O(n)\). La razón de esto radica en cómo Python elige implementar las listas. Cuando un elemento se toma del frente de la lista, en la implementación de Python, todos los demás elementos de la lista se desplazan una posición más cerca del inicio. Esto puede parecer tonto ahora, pero si nos fijamos en la Tabla 2 veremos que esta implementación también permite que la operación de indización sea \(O(1)\). Éste es un sacrificio mutuo que los implementadores de Python pensaron que era bueno.
Operación |
Eficiencia O-grande |
|---|---|
indización [] |
O(1) |
asignación indizada |
O(1) |
append |
O(1) |
pop() |
O(1) |
pop(i) |
O(n) |
insert(i,item) |
O(n) |
operador del |
O(n) |
iteración |
O(n) |
pertenencia (in) |
O(n) |
sacar una porción [x:y] |
O(k) |
eliminar una porción |
O(n) |
asignar una porción |
O(n+k) |
reverse |
O(n) |
concatenar |
O(k) |
ordenar |
O(n log n) |
multiplicar |
O(nk) |
Como una forma de demostrar esta diferencia en el desempeño vamos a hacer otro experimento usando el módulo timeit. Nuestro objetivo es poder verificar el desempeño de la operación pop en una lista de un tamaño conocido cuando el programa extrae del final de la lista, y de nuevo cuando el programa extrae del inicio de la lista. También queremos medir este tiempo para listas de diferentes tamaños. Lo que esperamos ver es que el tiempo requerido para extraer del final de la lista se mantendrá constante incluso cuando el tamaño de la lista crezca, mientras que el tiempo para extraer del inicio de la lista seguirá aumentando a medida que la lista crece.
el Programa 4 muestra un intento de medir la diferencia entre los dos usos de pop. Como se puede ver en este primer ejemplo, extraer del final toma 0.0003 milisegundos, mientras que extraer del inicio toma 4.82 milisegundos. Para una lista de dos millones de elementos esto es un factor de 16,000.
Hay un par de cosas para notar en el Programa 4. La primera es la instrucción from __main__ import x. Aunque no definimos una función, sí queremos poder usar el objeto lista x en nuestra prueba. Este enfoque nos permite medir el tiempo de la instrucción pop sola y obtener la medida más precisa del tiempo para esa única operación. Debido a que el temporizador se repite 1000 veces, también es importante señalar que la lista está disminuyendo su tamaño en 1 cada vez a lo largo del ciclo. Pero ya que la lista inicial tiene un tamaño de dos millones de elementos, sólo reducimos el tamaño total en un \(0.05 \%\)
Programa 4
extraerInicio = timeit.Timer("x.pop(0)",
"from __main__ import x")
extraerFinal = timeit.Timer("x.pop()",
"from __main__ import x")
x = list(range(2000000))
extraerInicio.timeit(number=1000)
4.8213560581207275
x = list(range(2000000))
extraerFinal.timeit(number=1000)
0.0003161430358886719
Si bien nuestra primera prueba muestra que pop(0) es más lento que pop(), este resultado no valida la afirmación de que pop(0) es \(O(n)\) mientras que pop() es \(O(1)\). Para validar esa afirmación necesitamos ver el desempeño de ambas llamadas en un rango de tamaños de listas. El Programa 5 implementa esta prueba.
Programa 5
extraerInicio = Timer("x.pop(0)",
"from __main__ import x")
extraerFinal = Timer("x.pop()",
"from __main__ import x")
print("pop(0) pop()")
for i in range(1000000,100000001,1000000):
x = list(range(i))
pt = extraerFinal.timeit(number=1000)
x = list(range(i))
pz = extraerInicio.timeit(number=1000)
print("%15.5f, %15.5f" %(pz,pt))
La Figura 3 muestra los resultados de nuestro experimento. Se puede ver que a medida que la lista se alarga, el tiempo que tarda pop(0) también aumenta mientras que el tiempo para pop se mantiene muy estable. Esto es exactamente lo que esperábamos ver para algoritmos \(O(n)\) y \(O(1)\), respectivamente.
Algunas fuentes de error en nuestro pequeño experimento incluyen el hecho de que hay otros procesos que se ejecutan en el equipo a medida que hacemos las mediciones y que pueden ralentizar nuestro código, así que a pesar de que tratemos de minimizar otras cosas que suceden en la computadora, es posible que haya alguna variación en el tiempo. Es por eso que el ciclo ejecuta la prueba mil veces con el fin de reunir información estadísticamente suficiente y hacer fiable la medición.
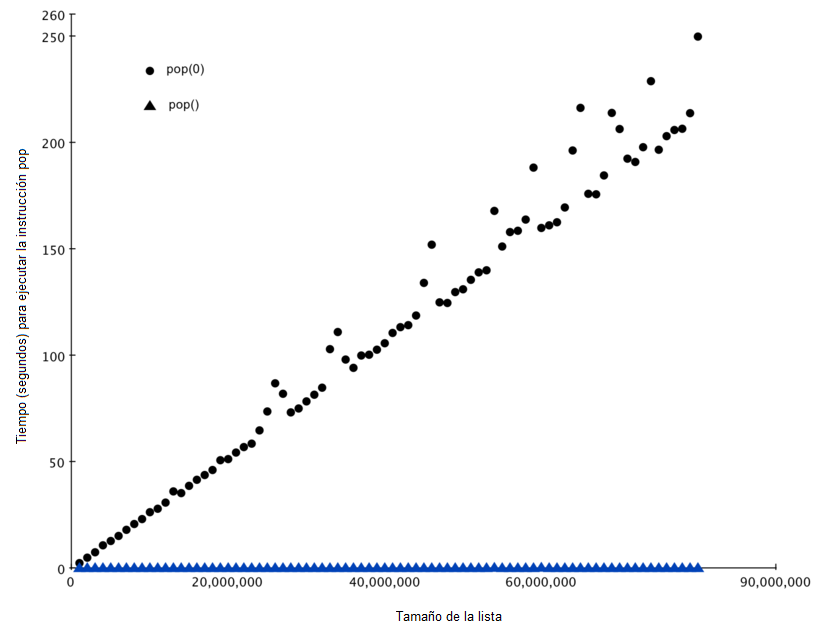
Figura 3: Comparación de los desempeños de pop y pop(0)¶
Figura 3: Comparación de los desempeños de pop y pop(0)