
Section 1: Generating HTML¶
We have generated HTML using our Web Microworld blocks in Snap. For example, here’s a very tiny web page definition in Snap blocks.

This generates a page that looks like this

The Snap stage shows us the HTML that was generated for this page. Remember this – we’ll compare to it later.

The Python Version¶
Here is a Python program that does the exact same thing as the Snap blocks above. Click “Run” to see the HTML that this generates.
The execution of this program looks pretty similar to what appears on the stage. Both the Snap and Python programs generate the same HTML. They are doing the same tasks.
The Python code might look longer and more complicated, but part of that is because of abstraction. We gave you a set of blocks that hides some of the details. Here is what is inside the “Make a Heading” block. Looks pretty close to the start of the Python program, isn’t it? The block hides away a lot of the detail and complexity – that’s abstraction.

Let’s go through how this works:
We are defining two functions using def. That is the keyword in Python for defining functions. One function is for creating headers. The other is for creating paragraphs. We use “+” to combining strings, like join in Snap.
We are building the HTML for our webpage in the variable webpage.
Instead of webpage = webpage +, Python gives us a short form: webpage += that adds something to the end of the webpage variable.
At the end, we print the HTML in the variable webpage.
Try answering these questions about the Python code above.
- webpage += header(2,"Here is more Information")
- Yes, exactly right.
- webpage += header2("Here is more Information")
- No, there is no function `header2`. The function name is `header` and it takes two inputs: A heading level and text for the heading, in that specific order..
- header(2,"Here is more Information")
- No, that calls `header` funciton but does not insert it into the webpage.
- <h2>Here is more Information</h>
- No, that is the HTML we want to generate. That is not valid Python code.
Q-2: If you wanted a second level heading that said “Here is More Information,” you would insert it right after line 9. which line of Python code would you insert? (Feel free to try it to see which works.)
- Tells Python that we are going to create a Webpage
- No, Python doesn't know what a webpage is.
- Creates a variable named webpage and puts the text for body in it.
- Yes. No declaration is needed.
- Declares the variable webpage to have type body
- No, there is no type named "body"
- Creates a string variable named webpage
- Kind of -- it creates as a "string" variable by putting a string in the variable.
Q-3: What does webpage = “<body>” do?
- Indentation - the lines indented under def are part of the definition.
- Yes. It's an odd feature of Python.
- Curly braces and semi-colons, like in Java or C.
- No, there are no curly braces or semi-colons in this example.
- Machine learning.
- No, indentation tells Python how the code is structured.
Q-4: How does Python know what lines of Python code are inside the function definitions for header() and paragraph()?
Section 2: Scraping HTML¶
We built a set of blocks in Snap Web Microworld blocks that allow us to pull the content out of Web pages and scrape that content. That is, we figure out what parts we want and return it.
Here, we grab all the URLs from this website, where the ebook is located.

The result looks like this:
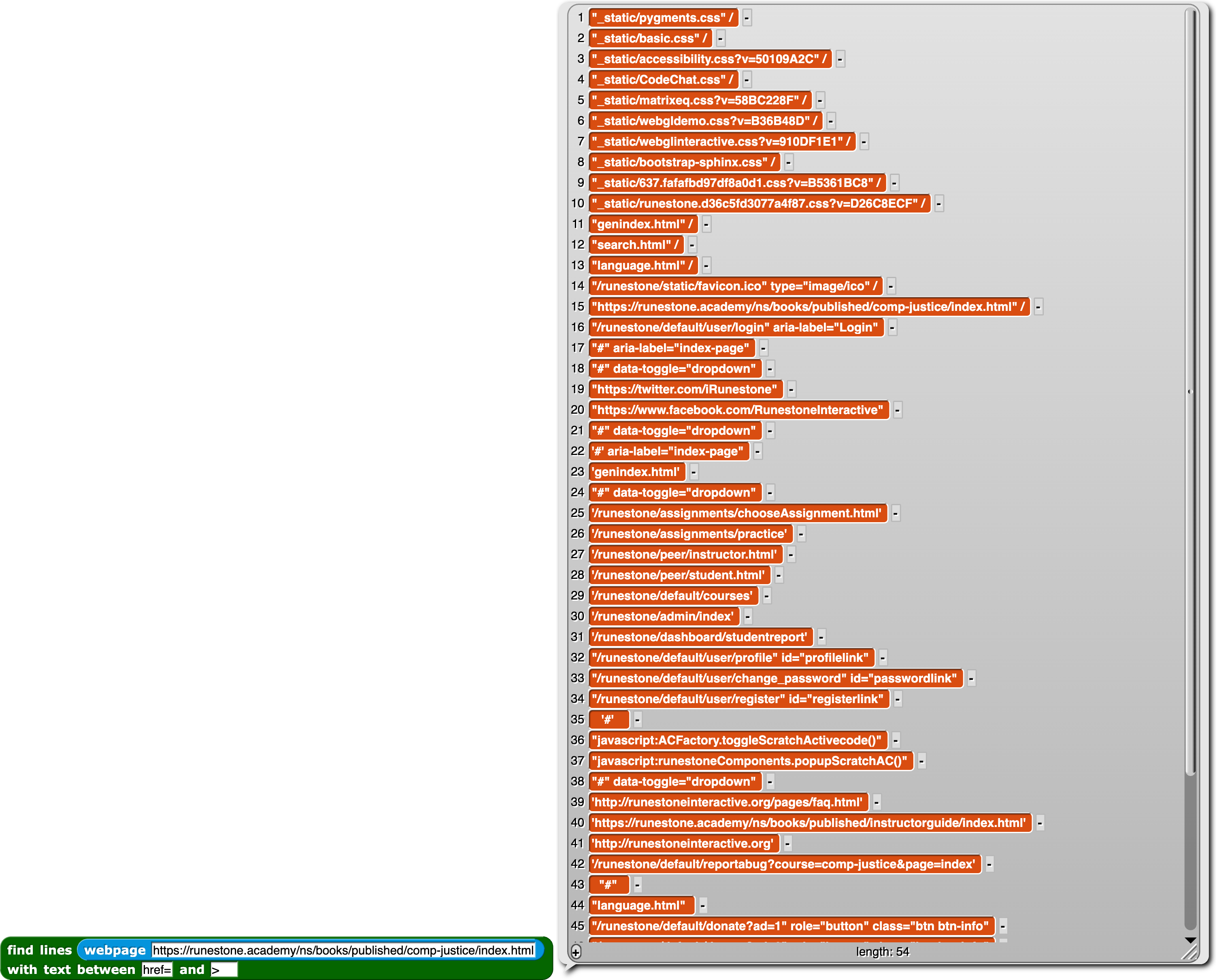
The Python Version¶
Here is a Python program that does the exact same thing as the Snap blocks above. Click “Run” to see what it generates.
Let’s go through how this works:
We are loading a library called requests which gives us the ability to read URLs.
We are defining a function web_scraper that takes a URL, then we get the content. That content is split into parts. We look for “href” in the part, then strip away the “href=”. We print what’s left.
The very last line is the one that calls the function web_scraper on this website.
Try answering these questions about the Python code.
- True. Library names are up to the user.
- No. You can call your own libraries and your own variables and functions whatever you want. Python's libraries must be named as specified.
- False. Library names are specific and must be typed exactly.
- Yes, Python is particular about how its libraries are called.
Q-6: The first line “import requests” is relatively arbitrary. We could change it to “import my requests” and it would still work. (Go ahead and try it!)
- True. Function names are defined by the programmer.
- Yes. Function names should be understandable, start with a letter, and follow a few other restrictions. But could be just about anything.
- False. This is web scraping, so it must be called web_scraper.
- No, it's really up to the programmer.
Q-7: The function web_scraper in line 3 could be anything, as long as we match it to the function call in line 10.
- reqs is defined in the library requests, and it sets the library to only work with split text.
- No, reqs is a variable that was defined in line 4.
- reqs is a variable defined in line 4. reqs.text returns the text of the URL, and split() chops it into pieces.
- Exactly right. reqs is defined by the programmer.
- reqs.text.split() means "Split up the words and go through each one."
- No, the "for string in" part is what starts going through each piece. reqs.text.split() generates the pieces for the variable "string" to be set to.
Q-8: What is reqs.text.split() doing?
- lstrip is short for link strip, and it strips the link from the HTML.
- No, Python doesn't know what a link is.
- lstrip is for Larry's strip, which is defined for Larry Page of Google -- it's his favorite function.
- No, I have no idea what Larry Page's favorite Python function is.
- It removes the given string "href=" from the variable "string" starting at the left (hence Lstrip)
- Exactly right -- this is how we get what the href= points at.
Q-9: What does lstrip(‘href=’) do?
Section 3: Reading HTML¶
You have built HTML pages, and seen the HTML that gets generated by the blocks. Below are Parsons Problems. For each of these, we give you the HTML, but scrambled. Drag them into the right order, then press the “Check” button to see if you got it right.
Put the blocks into order to define a simple HTML page. The Head comes before the Body, and the Title is inside the Head.
Put the blocks in order to create an HTML page with a body that contains an H2 header, a paragraph, and a link to another page. Only one of the H2 links below is correct – pick the right one, please.
Put the blocks into order to define a simple HTML page. Indent the blocks to show the structure. Note that the “head” comes before the “body” and the title is defined in the head. The body should contain a paragraph with a link in it.