
15.1. Divide Operator: two types¶
Divide is an original relational algebra operation [1] defined by Edgar F. “Ted” Codd, the inventor of the relational model of data [2] , [3]. As we come close to the end of our adventure with the relational model, it seems only fitting to give deference to its creator for one of the outstanding contributions to computer science that has stood the test of time. Here are a few references about his work.
References
Along with what we have already studied (project and reduce, filter, which Codd called selection, the set operations, times, and the various joins), Codd also described an operation called Divide, which is slightly more complicated to understand and which does not have a direct implementation in SQL, but can nonetheless be performed in SQL with a series of the other operations. We will describe and provide examples of Codd’s original version, and later look at another version that is also quite useful.
15.1.1. Divide, originally: “matches at least”¶
The basic principle of the original Divide is very powerful, and is worth learning. Knowing how to use it can enable you to perform some very interesting analyses. The idea of this binary operation is as follows:
First create an Input Relation A from your data that contains 2 columns. Some, usually not all, of the values in the first column is what will ultimately be returned. The second column contains values that will be compared to relation B. (for example: creatureId, skillCode of Achievement)
Next define a brand new Pattern Relation B that contains a single column of values in the universe of the second column of Input Relation A. This is a relation you typically make up on your own because it represents a pattern of values you would like to match to rows in input relation A. (for example: skillCode of Survivor Skills)
After performing the operation A Divide B, the result relation contains values from the first column of input relation A that satisfy this concept: For a given value in column 1 of A, among its rows of A, each column 2 of A matches at least all of the rows in the pattern relation B. (for example, creatureId of creature who as at least achieved Survivor Skills)
This definition is still possibly obtuse and hard to follow, so a full small example is the best way to see what this means. Let’s start by recalling what is in the Achievement relation, which looks like this:
achId |
creatureId |
skillCode |
proficiency |
achDate |
test_townId |
|---|---|---|---|---|---|
1 |
1 |
A |
3 |
2020-07-24 21:37:53 |
a |
2 |
1 |
E |
3 |
2017-09-15 15:35:00 |
d |
3 |
1 |
A |
3 |
2018-07-14 14:00:00 |
a |
4 |
1 |
E |
3 |
2020-07-24 21:37:53 |
d |
5 |
5 |
Z |
6 |
2016-04-12 15:42:30 |
t |
6 |
3 |
Z |
4 |
2018-07-15 00:00:00 |
be |
7 |
3 |
Z |
4 |
2018-07-15 00:00:00 |
be |
8 |
3 |
Z |
4 |
2018-07-15 00:00:00 |
be |
9 |
4 |
Z |
3 |
2018-06-10 00:00:00 |
a |
10 |
11 |
PK |
10 |
1998-08-15 00:00:00 |
le |
11 |
12 |
PK |
10 |
2016-05-24 00:00:00 |
le |
12 |
13 |
PK |
10 |
2012-08-06 00:00:00 |
le |
13 |
8 |
PK |
1 |
NULL |
t |
14 |
9 |
THR |
10 |
2018-08-12 14:30:00 |
mv |
15 |
10 |
THR |
10 |
2018-08-12 14:30:00 |
mv |
16 |
7 |
B2 |
19 |
2017-01-10 16:30:00 |
d |
17 |
9 |
B2 |
19 |
2017-01-10 16:30:00 |
d |
18 |
4 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
19 |
5 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
20 |
2 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
21 |
1 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
22 |
9 |
D3 |
8 |
2020-07-24 16:37:53 |
sw |
23 |
13 |
D3 |
8 |
2020-07-24 16:37:53 |
sw |
24 |
7 |
D3 |
8 |
2020-07-24 16:37:53 |
sw |
Note that creatures with particular creatureId values have achieved skills with particular skillCode values, sometimes more than once. The concept of using divide on this type of intersection entity is that we can define a minimum set of skills that, if achieved, constitute having met some criteria.
Suppose we have this basic English narrative:
Find each Creature who is a survivor because they can at least float and swim.
The skillCode for float is ‘A’ and for swim is ‘E’.
The precedence chart using the Divide operator symbol we have chosen (a triangle) looks like this:
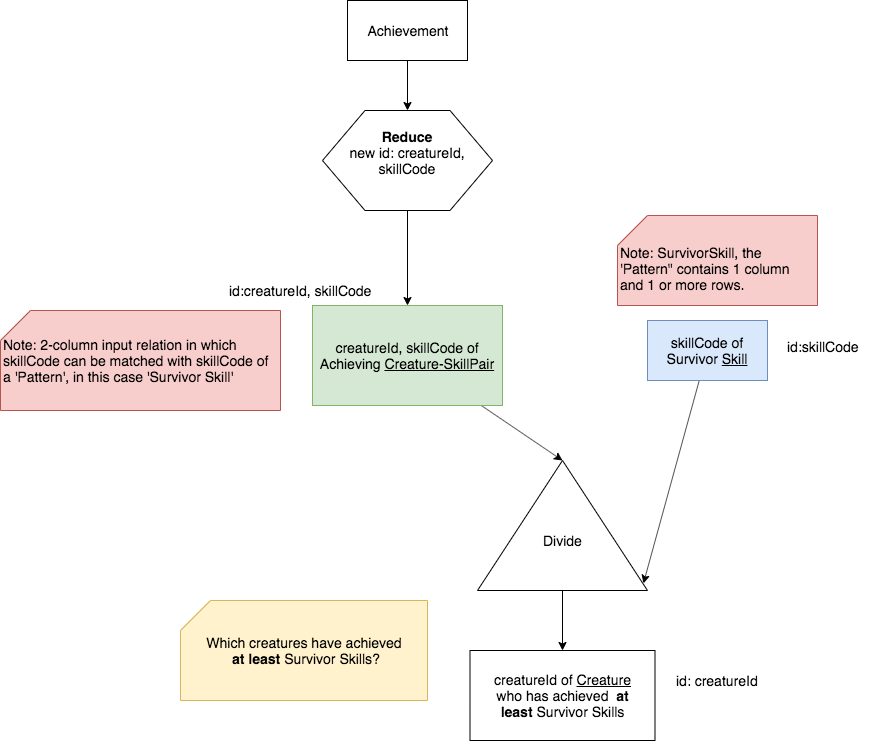
Note
One key point to understanding Divide is the words that have been bolded several times so far to emphasize this point: at least. The name of the result relation should contain this phrase, because it is a good way to understand what is in the result.
We will start with a compact, yet somewhat complex version of the SQL code. Run the following to see which creatureId identifies the survivor creature because they have achieved at least swim and float skills.
Shortly we will break this down into all of its parts using a much longer process with intermediate relations. But first note that when you feel comfortable with the nested query shown above, the generic form of it that you can use to devise your own queries looks like the following. Study this carefully and use it as a template when you try your own new queries.
-- A divide "at least" method made popular by C. Date in his textbooks.
--
-- [input] should be replaced by relation to match pattern with (A).
-- [Pattern] should be replaced by relation containing pattern rows (B).
-- [col1_of_input] should be replaced by column of values to be returned
-- that fulfill or match all the pattern row values.
-- [col_of_pattern] should be replaced by column name in Pattern relation.
-- Note that this same column name should exist in [input],
-- which should have both [col1_of_input] and
-- [col_of_pattern] in it.
SELECT DISTINCT [col1_of_input]
FROM [input] AS IN1
WHERE NOT EXISTS
(SELECT *
FROM [Pattern]
WHERE NOT EXISTS
(SELECT *
FROM [input] AS IN2
WHERE (IN1.[col_of_input] = IN2.[col1_of_input])
AND (IN2.[col_of_pattern] = [Pattern].[col_of_pattern])
)
);
Let’s unpack this convenient fill-in-the blank version, using our original query, “Find each Creature who is a survivor because they can float and swim.”
Here is a longer precedence chart showing how we can complete the divide operation. When you work, you don’t have to use a chart like this, you can use the simple one above. However, we will present the details here one so that you can see how it gets done. Note how this chart below has two minus operations, which can be accomplished in SQL using ‘NOT EXISTS’; this is why the above template has two uses of this.
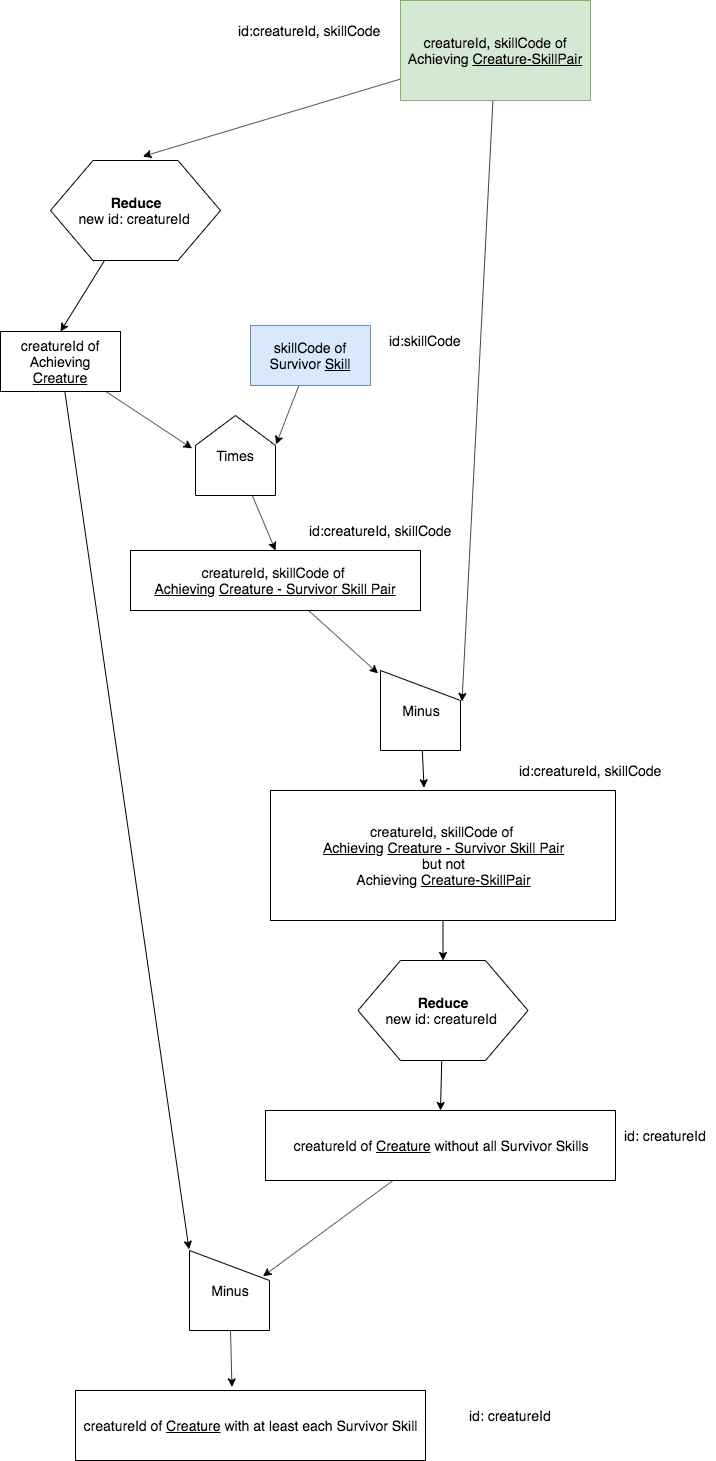
Next we can look at a translation of the above chart into a long version of SQL that uses several intermediate relations. Each tab completes part of the above chart. Run the last one to see that it gets the same result.
The above was simply an illustration of all the steps, so you get a sense of how the NOT EXISTS syntax can be used for the minus operator. Perhaps you can see how this long version translates into the much more compact, nested query version that we presented first, repeated as follows:
-- A divide "at least" method made popular by C. Date in his textbooks.
--
-- [input] should be replaced by relation to match pattern with (A)
-- [Pattern] should be replaced by relation containing pattern rows (B)
-- [col1_of_input] should be replaced by column of values to be returned
-- that fulfill or match all the pattern row values
-- [col_of_pattern] should be replaced by column name in Pattern relation
-- Note that this same column name should exist in [input],
-- which should have both [col1_of_input] and
-- [col_of_pattern] in it.
SELECT DISTINCT [col1_of_input]
FROM [input] AS IN1
WHERE NOT EXISTS
(SELECT *
FROM [Pattern]
WHERE NOT EXISTS
(SELECT *
FROM [input] AS IN2
WHERE (IN1.[col_of_input] = IN2.[col1_of_input])
AND (IN2.[col_of_pattern] = [Pattern].[col_of_pattern])
)
);
The first minus tab in the long version corresponds to the second ‘WHERE NOT EXISTS’ in the compact version, and the second minus tab in the long version corresponds to the first ‘WHERE NOT EXISTS’ in the compact version.
Important
To use the compact version, you will need to create the input and Pattern relations first. In many cases you can use a relation like Achievement as is for the input, but it’s just as well to create the 2-column version instead. You always have to create the Pattern to match against.
15.1.2. Exactly Divide: matching the pattern exactly (no more, no less)¶
Another useful version of Divide has a slightly different meaning. We still have a ‘Pattern’ relation B and an input relation A, but this time we wish to return those in A that match exactly, no more or no less, what is in the Pattern B.
Let’s examine this by comparing it to the previous “at least” version. Here are two different English queries:
Find each creature who has achieved at least the skill whose description is ‘three-legged race’.
Find each creature who has achieved exactly the skill whose description is ‘three-legged race’.
Note
When it is one skill such as this example, we might have also said “find each creature who has achieved only the skill whose description is ‘three-legged race’.”
Here is a precedence chart for this, where we use filter and project to get the three-legged race skill for the Pattern relation called ‘skillCode of three-legged race’, Have the same input relation shown in green as before, and change the operator symbol in one minor way, which is to add the word exactly after divide. We also change the result relation name accordingly.
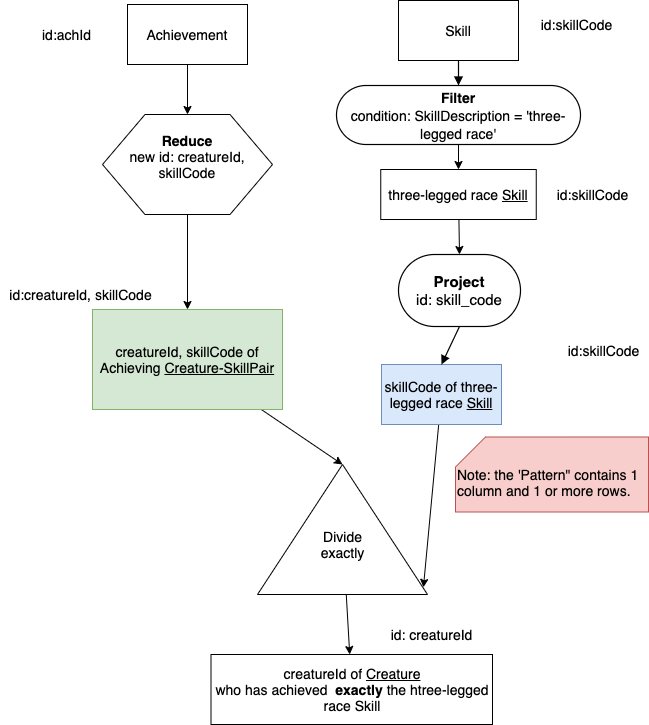
Now let’s go through the complex SQL for this sophisticated example. First, we need to make the ‘pattern’ relation with one column (and in this simple case one skill).
Now the at least divide as we presented before:
And next the ‘exactly’ three-legged race, no more no less.
As you might have thought, determining whether achievements per creature matches a pattern exactly needs to involve counting the number of skills in the pattern, the number of skills corresponding to the pattern that have been achieved per creature, and the number of skills total that have been achieved by the creature. This above query accomplishes this in yet another compact, yet complicated form. This is the most complicated query you will see in this book. Exact pattern match is the hardest type of query to perform, but when you can do it using the following general for as a guide, you can feel like you have mastered an important part of relational data analysis.
As an exercise, you could try to work out a long form chart for the query above.
General form for Divide exactly. Here is a general form of the above query for any input A and Pattern B. You can use this as you practice and create queries of your own.
-- This one is the generic form of "exactly divide", or exactly the
-- number of values in the 1-column rows in pattern relation Pattern.
--
-- [input] should be replaced by relation to match pattern with.
-- [Pattern] should be replaced by relation containing pattern rows.
-- [col_of_input] should be replaced by column of values to be returned
-- that fulfill or match all the pattern row values.
-- [col_of_pattern] should be replaced by column name in Pattern relation.
-- Note that this same column name should exist in [input],
-- which should have both [col_of_input] and
-- [col_of_pattern] in it.
SELECT IN1.[col_of_input]
FROM [input] AS IN1
LEFT OUTER JOIN
[Pattern] AS P1
ON IN1.[col_of_pattern] = P1.[col_of_pattern]
GROUP BY IN1.[col_of_input]
HAVING COUNT(IN1.[col_of_pattern]) =
(SELECT COUNT([col_of_pattern]) FROM [Pattern])
AND COUNT(P1.[col_of_pattern]) =
(SELECT COUNT([col_of_pattern]) FROM [Pattern]);
15.1.3. Try yourself¶
Suppose it is useful to have debating skills along with being accomplished as a soccer player if you want to be a spokesperson for your club. Yet it is best if the spokesperson is not encumbered with any other achievements not associated with soccer. We might ask this:
Who has achieved exactly ‘soccer penalty kick’ and ‘Australasia debating’ skills?
Use this code block to complete the query from the generic template above by filling in where it says ‘fill here’ below.
More ideas to try:
Who has achieved in at least Duluth (‘d’) and Metroville (‘mv’) towns?
What has been achieved by at least ‘Kermit’ and ‘Thor’?
Note that things change more for these- the first still returns creatureId from Achievement, but the Pattern column is different (townId instead of skillCode). The second uses creatureId values as the Pattern, and returns skillCode values.
Another Reference
If you are enjoying the complexity of this Divide operation, you might find this article by Joe Celko about divide quite interesting. He describes a few even more complex examples, along with an explanation of what I have shown here with a different example.
15.1.4. Exercises¶
Try creating the precedence charts for these queries. Use the simple version with the triangle-shaped divide (exactly) operator.
English Query:
Find each Creature who is a superman because they can do all of the skills.
Find each Creature who has achieved at least float, swim, and run 4x100 meter track relay.
Find each creature who aspires to exactly gargle and 2-person canoeing skills.