
9.5. Group¶
Group is the fourth unary operator. It calculates aggregate values (simple statistics) from its input relation’s cell values. About Group there are four key notions to learn. Read these now, then review them later after you study the examples that follow.
Group has 2 circumstances where a statistic or statistics are calculated by:
Partitioning (or grouping – thus the operator name) the input relation into one set of rows, Grouping over no columns. An example English query for this circumstance is:
“Find the count of all creatures.”
Partitioning the input relation into many sets of rows, Grouping over one or a few columns that have the same value(s). An example English query for this circumstance is:
“For each creatureId, count the number of its achievements”
Every Group has a non-relation input which is a list of aggregate functions with result column names, for example, “achievementCount” for 1.b. above. The aggregate functions specifiable in SQL include: Sum, Count, Minimum, Maximum, Average, Variance, and Standard Deviation. In computing these aggregates, SQL generally ignores NULL values. However, Count has two forms. You can specify Count(*) , or Count(<column-name>). For each group of rows, the former ignores cell values and just counts the number of rows, while the latter counts the number of non-NULL cell values in that column.
Group’s computed columns differ from computed columns in Project. When you compute values with a Project you think horizontally. A Project computed column “numProficiencyValues = maxProficiency - minProficiency” uses values within one row (horizontally related) to compute a new column. You think about scalar variables, constants, and simple arithmetic functions. However, with Group you think vertically, and “achievementCount = count(*)” computes a value for each group of many vertically-related rows. In programming terms, you think about array or vector, not scalar arithmetic.
Important
Group seems “easy.” However, some novices never master it. I think that failure often can be attributed to not learning to think vertically.
Grouping over one or a few columns emerges from Reduce. Look at the relation in the first example SQL result below and cover the computed aggregate column. What remains visible is what would result if you Reduce Achievement to creatureId. You can more quickly master Group if you see a Reduce lurking within it. Because it is like Reduce, Group is dangerous in much the same ways that Reduce was. Because it is like Reduce, the symbol that was use in precedence charts is the same.
9.5.1. Example 1: Group over one column¶
Let’s remember what is in the achievement data relation, since we will try some queries on it.
achId |
creatureId |
skillCode |
proficiency |
achDate |
test_townId |
|---|---|---|---|---|---|
1 |
1 |
A |
3 |
2020-07-24 21:37:53 |
a |
2 |
1 |
E |
3 |
2017-09-15 15:35:00 |
d |
3 |
1 |
A |
3 |
2018-07-14 14:00:00 |
a |
4 |
1 |
E |
3 |
2020-07-24 21:37:53 |
d |
5 |
5 |
Z |
6 |
2016-04-12 15:42:30 |
t |
6 |
3 |
Z |
4 |
2018-07-15 00:00:00 |
be |
7 |
3 |
Z |
4 |
2018-07-15 00:00:00 |
be |
8 |
3 |
Z |
4 |
2018-07-15 00:00:00 |
be |
9 |
4 |
Z |
3 |
2018-06-10 00:00:00 |
a |
10 |
11 |
PK |
10 |
1998-08-15 00:00:00 |
le |
11 |
12 |
PK |
10 |
2016-05-24 00:00:00 |
le |
12 |
13 |
PK |
10 |
2012-08-06 00:00:00 |
le |
13 |
8 |
PK |
1 |
NULL |
t |
14 |
9 |
THR |
10 |
2018-08-12 14:30:00 |
mv |
15 |
10 |
THR |
10 |
2018-08-12 14:30:00 |
mv |
16 |
7 |
B2 |
19 |
2017-01-10 16:30:00 |
d |
17 |
9 |
B2 |
19 |
2017-01-10 16:30:00 |
d |
18 |
4 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
19 |
5 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
20 |
2 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
21 |
1 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
22 |
9 |
D3 |
8 |
2020-07-24 16:37:53 |
sw |
23 |
13 |
D3 |
8 |
2020-07-24 16:37:53 |
sw |
24 |
7 |
D3 |
8 |
2020-07-24 16:37:53 |
sw |
Note
Some creatures, such as that with creatureId=1, have achieved some skills more than once.
English Query:
For each creatureId, find the count of its achieved skills.
Note that this is different than counting all of a particular creature’s achievements, even if the same skill was achieved more than once.
Precedence Chart:
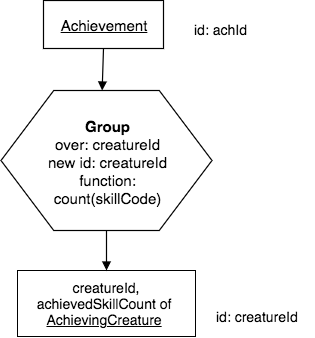
Corresponding SQL:
The keyword distinct in the query above is important. Notice what happens to creatureId 1’s count if you remove it and run it again. In the latter case, you are simply counting all achievements, regardless of whether the same skill is duplicated because it was achieved twice or more by some creature.
9.5.2. Example 2: Group over multiple columns¶
English Query:
For each creatureId and skillCode, find the count of how many times the creature achieved the skill.
Note that if the same skill was achieved more than once, we can now count how many times that happened.
Precedence Chart:
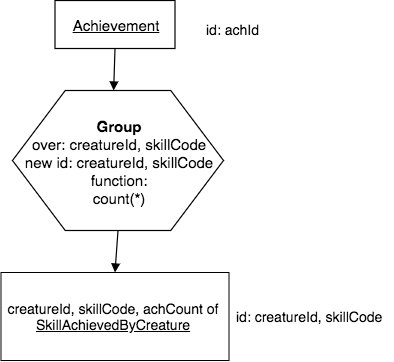
Corresponding SQL:
Note that we can simply count the number of rows by using an asterisk, ‘*’ inside the function parentheses, as shown in the above example.
9.5.3. Example 3: Group over no columns¶
English Query:
Find the maximum proficiency of any achieved skill.
Note
It is important that you realize that this query returns a single cell value in one row and one column in the result relation.
Precedence Chart:
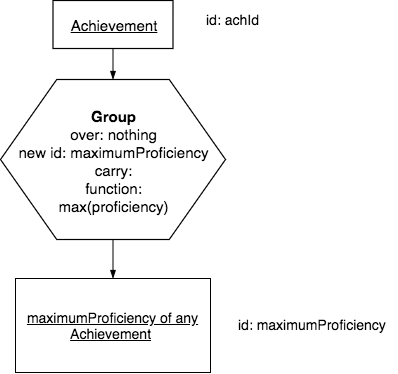
Note
Think: In this above chart, contemplate why the result relation is named the way it is. In these cases, the base becomes a somewhat long name so that it accurately reflects the single statistic that will be computed.
Corresponding SQL:
Note
If you scroll back up and look at the achievement relation’s data, the only column on which we could compute a function like max, min, sum, or average is proficiency, because it contains an integer value. In some systems you can consider using max and min on date values, but that is highly system dependent.
You can also compute several of the statistics at once, like this:
Precedence Chart:
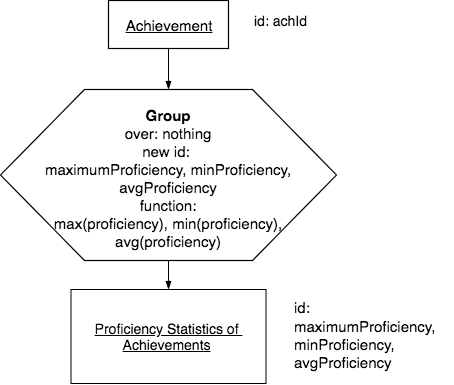
Note
Think: In this above chart, once again contemplate why the result relation is named the way it is (and that it is different than the previous example). As before, the base has a somewhat long name so that it accurately reflects what will be computed.
You try. Here is the previous query in SQL. You try adding to it to get the minimum and the average proficiency also.
9.5.4. Summary of Group Characteristics¶
As you have seen, the nature of the result relation is quite different between the two kinds of group. Let’s summarize the characteristics of each.
9.5.4.1. Group over no columns¶
For a Group over no columns circumstance: you specify a list of aggregate function – column name pairs; and the entire input relation is treated as one set of rows to aggregate over. The result relation has these notable name and structure characteristics.
Name characteristics:
Its base comes from the specified function columns.
It has a row modifier formed from the input relation’s name.
It has no column modifier.
The result relation’s identifier consists of all of its function columns.
Structure characteristics:
The result relation is one row tall, unless the input relation has zero rows.
It is as wide as the number of function columns specified.
9.5.4.2. Group over one or more columns¶
For a Group over one or a few columns circumstance, you specify, as before, an input relation, and a list of aggregate functions. Now you also specify one or a few columns to Group over. The result relation has these notable name and structure characteristics:
Name characteristics:
Its base comes from the specified Over columns.
It has a row modifier formed from the input relation’s name.
It has a column modifier formed from the function column names.
The result relation’s identifier consists of its Over columns.
Structure characteristics:
The result relation is as tall as the number of distinct rows there are when looking at just the Over columns.
It is as wide as the number of Over and function columns specified.
9.5.5. Bad Cases: Group, like Reduce, is dangerous!¶
There are two ways in which a bad group can arise.
Group with bad Over column. An Over column of a Group cannot have a NULL value in it because such a column is an identifying one in the result relation. For example, Grouping over idol_creatureId in Creature (shown below) yields a table, not a relation.
creatureId |
creatureName |
creatureType |
reside_townId |
idol_creatureId |
|---|---|---|---|---|
1 |
Bannon |
person |
p |
10 |
2 |
Myers |
person |
a |
9 |
3 |
Neff |
person |
be |
NULL |
4 |
Neff |
person |
b |
3 |
5 |
Mieska |
person |
d |
10 |
6 |
Carlis |
person |
p |
9 |
7 |
Kermit |
frog |
g |
8 |
8 |
Godzilla |
monster |
t |
6 |
9 |
Thor |
superhero |
as |
NULL |
10 |
Elastigirl |
superhero |
mv |
13 |
11 |
David Beckham |
person |
le |
9 |
12 |
Harry Kane |
person |
le |
11 |
13 |
Megan Rapinoe |
person |
sw |
10 |
Note
Run the above query. Notice how idol_creatureId should be the identifier of the new result, but one of its values is null.
Group with carry columns. For a Group with Over columns, carry columns are dangerous. You can avoid errors if you learn to see a Reduce within a Group. For example, if you look at the Creature relation above, imagine if we Reduce to creatureType. When grouping over creatureType, you might be tempted to want to carry a column like reside_townId, but what should it contain? The following code runs in SQLite, but is a dangerous, misleading result- try it.
Important
Though some systems allow this bad query, you really should avoid it in practice.
Carry columns are also dangerous for a Group with no Over columns. In general, it is once again simply a bad practice to try it.
9.5.6. Exercises¶
When working on precedence charts for these, recognize which ones are grouping over one or more columns and which ones are grouping over nothing. Which one is a potentially bad group?
How many towns are there?
Count each type of creature.
Count achieved skillCode of skills per tested town of achievement.
Count skillCode per originTownId of skill.
Count creatureId per resideTownId of creature.
Find the count of the number of creatures.
Find the count of the number of skills.
Find the highest maximumProficiency of any of the skills.
Find the skillDescription and lowest maximumProficiency of any of the skills.
Once you have a chart, try some SQL for 7 - 9 above. Here is what the Skill relation data looks like. Then below is a place for you to try completing the query. See whether the potentially bad query is indeed bad.
skillCode |
skillDescription |
maxProficiency |
minProficiency |
origin_townId |
|---|---|---|---|---|
A |
float |
10 |
-1 |
b |
B2 |
2-crew bobsledding |
25 |
0 |
d |
C2 |
2-person canoeing |
12 |
1 |
t |
D3 |
Australasia debating |
10 |
1 |
NULL |
E |
swim |
5 |
0 |
b |
O |
sink |
10 |
-1 |
b |
PK |
soccer penalty kick |
10 |
1 |
le |
THR |
three-legged race |
10 |
0 |
g |
TR4 |
4x100 meter track relay |
100 |
0 |
be |
U |
walk on water |
5 |
1 |
d |
Z |
gargle |
5 |
1 |
a |
Here is the bad group query, which asks for a carry column, skillDescription. Study the output to see what it is bad and misleading.
Find the skillDescription and lowest maximumProficiency of any of the skills.