
Plan 3: Get info from all tags of a certain type¶
To get information from the Cottage Inn locations page, we need to figure out which tags we should get from the soup, and what information we should get from the tags.
A great way to figure this out is to use the “inspect” function on your browser.
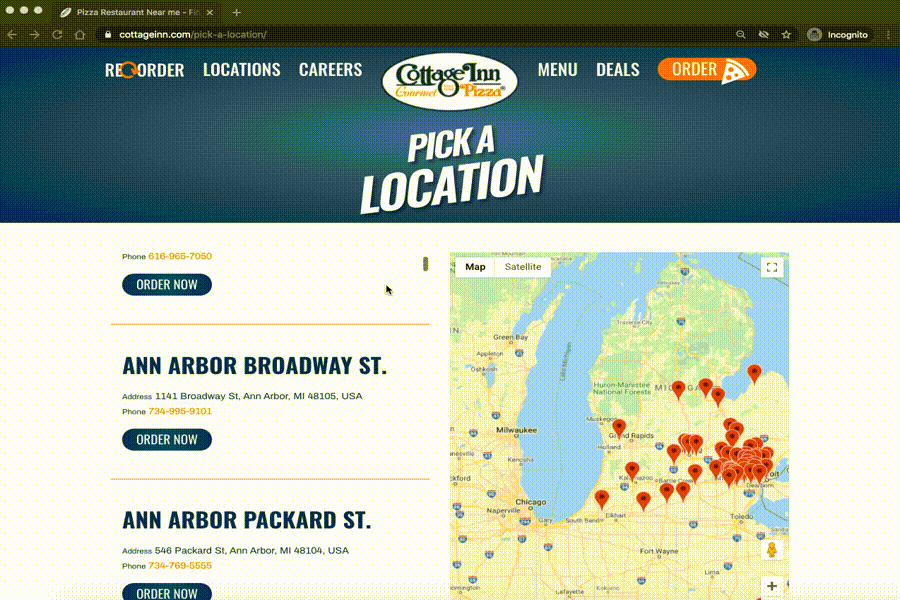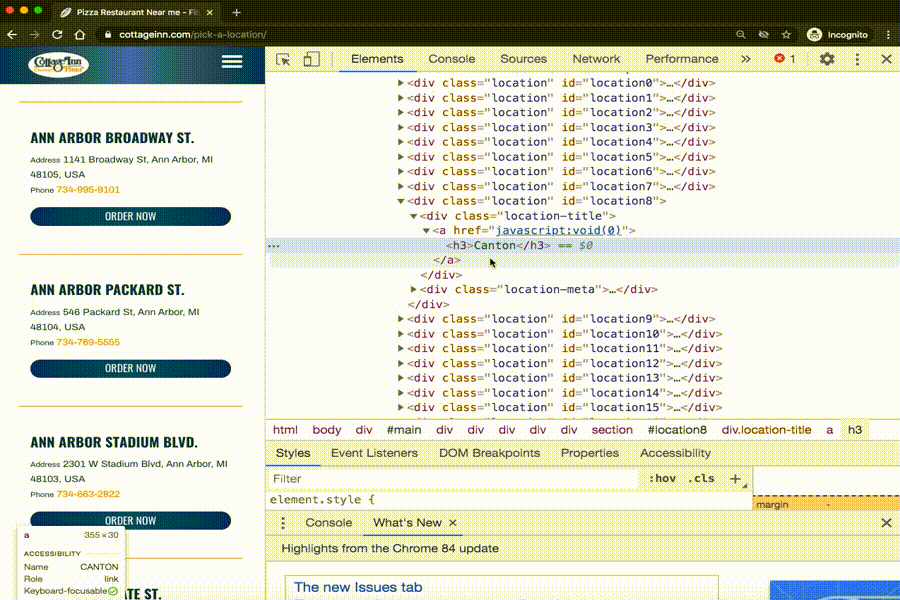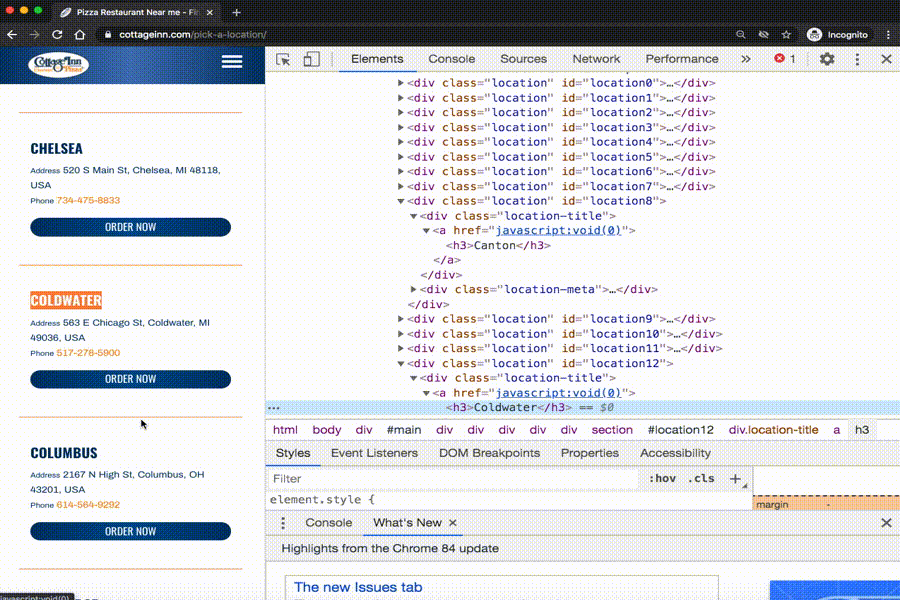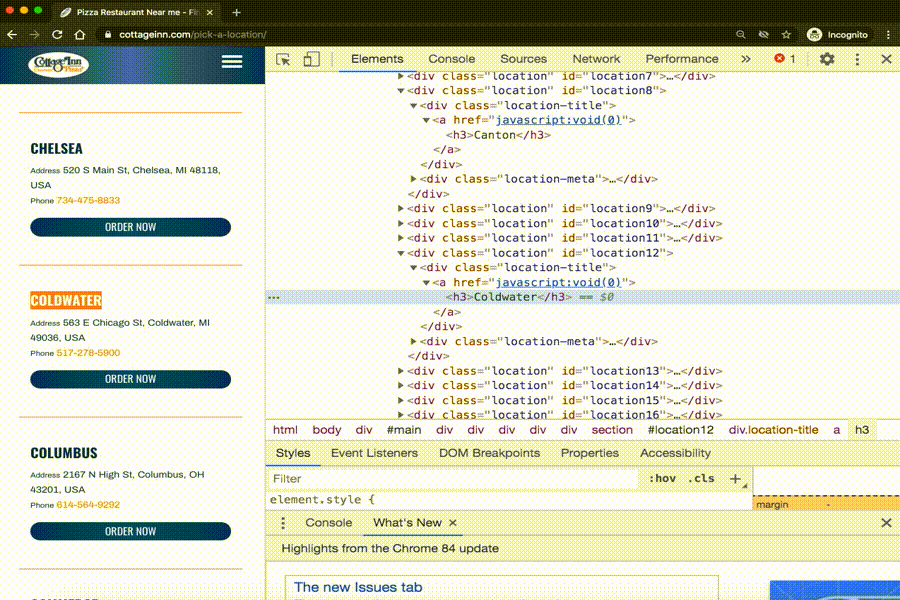
We see that we need to get info from all the h3 tags from the webpage. The text in those tags has the information we need!
Looking closer at a tag¶
Behind every webpage is HTML code. HTML code is made up of tags.
Here is the tag that creates the name of one of the Cottage Inn Pizza locations. The tag is surrounded by the blue rectangle. It is an ‘h3’ tag.

The name of this tag is ‘h3’. In-between the start and end tag (between the <h3> and </h3> is the tag’s text. For this tag, the text is Ann Arbor Broadway St.
Plan 3: Example¶
Here is how to get text from all the ‘h3’ tags from webpage:
Goal: Get info from all tags of a certain type
# Get all tags of a certain type from the soup
tags = soup.find_all('h3')
# Collect info from the tags
collect_info = []
for tag in tags:
# Get info from tag
info = tag.text
collect_info.append(info)Plan 3: How to use it¶
Once you’ve found the tags you want to get information from, do two things:
Find the tag description and put it into the first slot.
How do you do that? Here are some examples:
What you see when you inspect |
Tag description in the code |
|
|---|---|---|
|
-> |
|
|
-> |
|
|
-> |
|
|
-> |
|
|
-> |
|
Determine if you want to get text from a tag, or a link from a tag. Put that information into the second slot.
The info you want |
What you put in the code |
|
|---|---|---|
The tag’s text |
-> |
|
The tag’s link |
-> |
|
Plan 3: Exercises¶
Today’s Menu
-
Correct! This text is between the <h2 class=”menuItem”> and </h2>
h2
-
No, h2 is the tag name
menuTitle
-
No
class
-
No
p5-1: What is the text of the tag below?
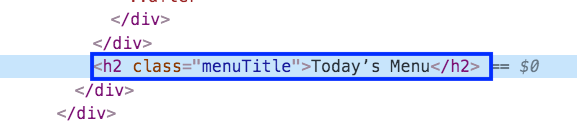
‘h2’, class_=’menuTitle’
-
Correct! This is how you would describe the tag type in our web scraping code.
‘h2’
-
That is a part of the tag description, but we can be more specific.
‘h2’, class=’menuTitle’
-
Very close, but in web scraping code you should use class_
<h2 class=”menuTitle”>
-
This is what is actually in the tag, but it’s not how we would describe the tag in web scraping code.
p5-2: What is the tag description of the tag below?
# Get all tags of a certain type from the soup tags = soup.find_all('h3') # Collect info from the tags collect_info = [] for tag in tags: # Get info from tag info = tag.text collect_info.append(info)
‘h2’
-
No, there is no h2 tag in this image.
span, style=’font-weight: 400;’
-
Correct! The text starts with “With its chandeliers and dramatically vaulted ceiling…”
‘p’
-
No, this tag contains the span tag.
‘style’
-
No, style is an attribute
p5-5: Which tag in the picture below has text?
