
🤔 Graphing Kiva Data with the Turtle¶
Computing statistics about numbers gives you a pretty narrow understanding of your data. Its really important to look at your data visually, that is to graph it. While there are many tools that you can use to graph your data, for this project we’ll be coding our own graphs from scratch. Don’t worry in the next lab we’ll explore one of the many high powered graphing tools that will will make the process easier. Its good to know how the tools work behind the easy to use interface, and writing the code for some of these tools makes for a good learning experience. Or as my dad would say: “It builds character.”
We will use turtle graphics to build three very useful graphs:
A Bar Chart
A Scatter plot
A Histogram
Bar Chart¶
A bar chart is a 2-dimensional plot that has a label on one axis (usually the X axis) and a value on the other axis (usually the Y axis). If the label is on the X axis we call it a vertical bar chart, and if the label is on the y axis we call it a horizontal bar chart.
The goal of this first exercise is to reproduce a bar chart that looks like this:
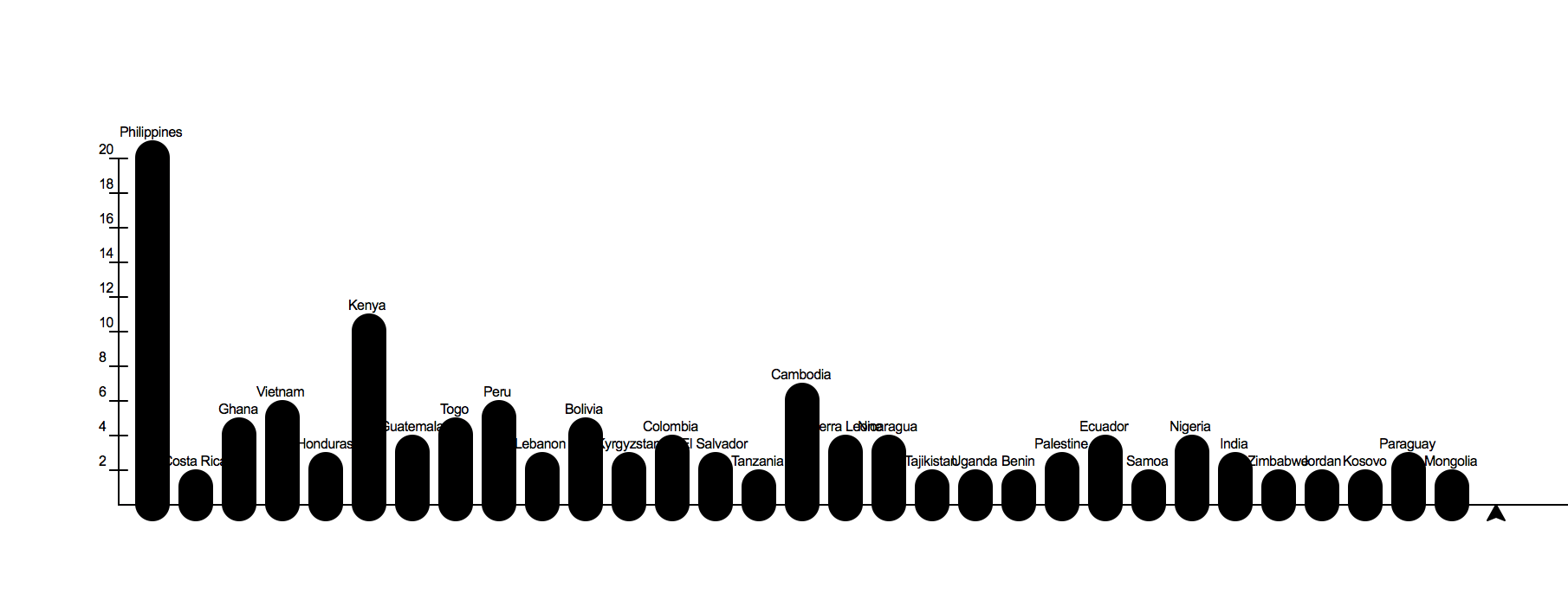
You can re-use the the unique_country list from the last project or if you have read enough about conditionals and list mutation you can make your own list of unique countries. This will allow you to count the number of loans made for each country.
To draw the bars you can cheat a litte bit and just make your turtle really fat by using a width of about 20. If you want to be really nice and precise you can draw a filled rectangle with the turtle too.
You should get the basics of the bar chart working first. Your very first try is likely to be kind of short and generally not very good looking. You’ll want to experiment with a scale factor to make your Y values lengthen themselves a bit. Later come back and draw the axes and scale and the labels for each country.
The data for this project is from the same original data set as the previous project, but we have provided a larger sample this time around.
Reproduce the bar chart above using the data provided and turtle graphics.
Scatter Plot¶
A scatter plot is one of the most useful graphs for data science and helping you understand the relationships between two variables. An example called “Anscombe’s Quartet” really helped me understand the importance of visualizing your data.
Here is a table that contains the data:
dataset |
x |
y |
|---|---|---|
I |
10.0 |
8.04 |
I |
8.0 |
6.95 |
I |
13.0 |
7.58 |
I |
9.0 |
8.81 |
I |
11.0 |
8.33 |
I |
14.0 |
9.96 |
I |
6.0 |
7.24 |
I |
4.0 |
4.26 |
I |
12.0 |
10.84 |
I |
7.0 |
4.82 |
I |
5.0 |
5.68 |
II |
10.0 |
9.14 |
II |
8.0 |
8.14 |
II |
13.0 |
8.74 |
II |
9.0 |
8.77 |
II |
11.0 |
9.26 |
II |
14.0 |
8.1 |
II |
6.0 |
6.13 |
II |
4.0 |
3.1 |
II |
12.0 |
9.13 |
II |
7.0 |
7.26 |
II |
5.0 |
4.74 |
III |
10.0 |
7.46 |
III |
8.0 |
6.77 |
III |
13.0 |
12.74 |
III |
9.0 |
7.11 |
III |
11.0 |
7.81 |
III |
14.0 |
8.84 |
III |
6.0 |
6.08 |
III |
4.0 |
5.39 |
III |
12.0 |
8.15 |
III |
7.0 |
6.42 |
III |
5.0 |
5.73 |
IV |
8.0 |
6.58 |
IV |
8.0 |
5.76 |
IV |
8.0 |
7.71 |
IV |
8.0 |
8.84 |
IV |
8.0 |
8.47 |
IV |
8.0 |
7.04 |
IV |
8.0 |
5.25 |
IV |
19.0 |
12.5 |
IV |
8.0 |
5.56 |
IV |
8.0 |
7.91 |
IV |
8.0 |
6.89 |
The interesting thing about this data is that if you calculate the standard deviation, the mean, the median, you will see that they are all the same!
x |
x |
x |
y |
y |
y |
|
|---|---|---|---|---|---|---|
mean |
std |
var |
mean |
std |
var |
|
dataset |
||||||
I |
9.0 |
3.31 |
10.99 |
7.50 |
2.03 |
4.12 |
II |
9.0 |
3.31 |
10.99 |
7.50 |
2.03 |
4.12 |
III |
9.0 |
3.31 |
10.99 |
7.50 |
2.03 |
4.12 |
IV |
9.0 |
3.31 |
10.99 |
7.50 |
2.03 |
4.12 |
In addition the correlation between the X and Y variables is 0.816 for all four groups.
Now for a big surprise Press the reveal button to see the different groups in graphical form.
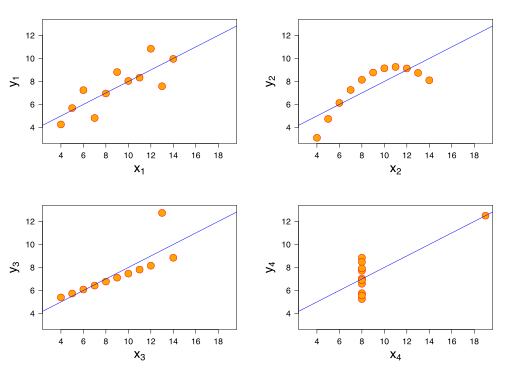
How amazing is that? Four datasets with exactly the same summary statistics and exactly the same correlation between the X and Y variables and yet they tell a completely different story when you graph them.
The amazing graphs in the example above are scatter plots of the X varable and the Y variable. We’ll make a similar plot for one or more pairs of the variables in our Kiva data.
Now, using the turtle Make a scatter plot of num_lenders_total on the X axis and loan_amount on the Y axis. When you make this graph You will need to scale the graph so that it fits in the window. The turtle graphics package provides us with a good way to do this using setworldcoordinates(llx, lly, urx, ury). This method allows us to give the values for X and Y that correspond to the lower left corner of the window as well as the values for X and Y that correspond to the upper right corner of the window. The turtle will automatically scale it movements according to those boundaries. What would be good values to choose for those four parameters?
Create a well scaled scatter plot with X and Y axes using num_lenders_total and loan_amount
Once you have the graph constructed think about what it tells you.
Write a short paragraph to explain the story told by the scatterplot you created.
Histogram¶
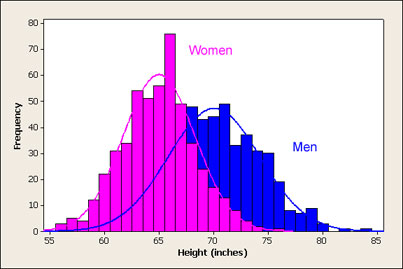
In one of our previous labs we calculated the variance and the standard deviation of a list of numbers. Either number gives us an indication of how much the data is spread out. But a histogram tells a much richer story. For example here is a histogram that shows the distribution of heights in women and men.
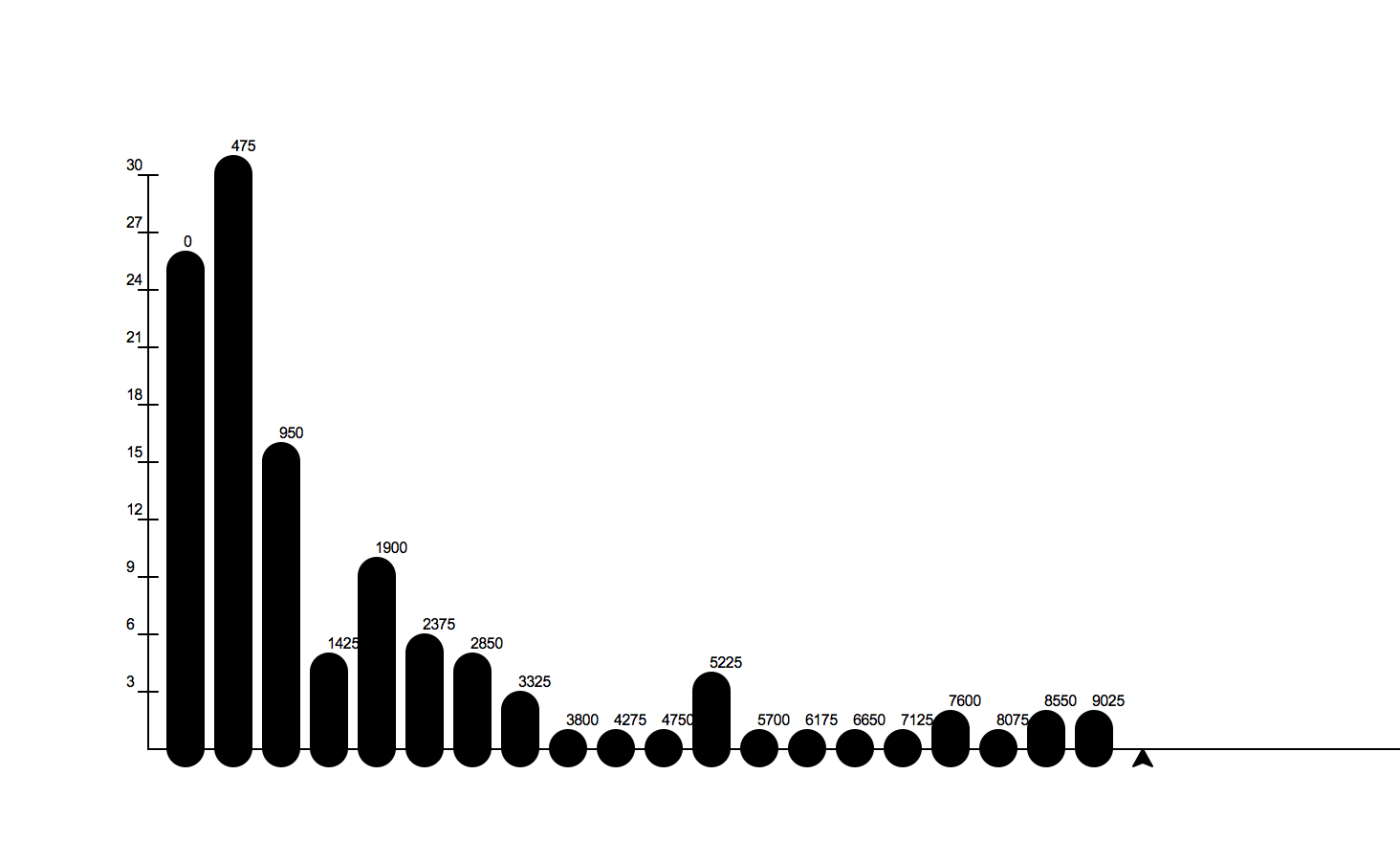
Here is a histogram of our kiva data and the amount of money loaned.
Notice that the graphs tell very different stories. One shows that most young women are close to the mean varying just a little on either side of the mean. Most young women are X inches tall plus or minus a couple inches. Sure there are a few that are much taller and a few that are much shorter. This graph is a great example of what we call a normal distribution. You have probably heard of the bell curve before and the histogram of heights is a great example.
The graph of kiva data is very different, what it says is that the vast majority of the loans are quite small with the amount tapering off quite quickly. But, there are a very few loans that are very large. In fact if you investigated these large loans you would find that they are all part of a new initiative at Kiva that is aimed at helping small businesses in the USA.
The idea behind graphing a histogram is that we first need to create the ‘categories.’ For a histogram the categories are really numerical ranges, that we will refer to as buckets. For many histograms the default is to put the data into 10 equal size buckets. For example if we had a bunch of numbers between 0 and 100 then we would have a bucket from 0-9 and another from 10-19 and another from 20-29 etc. The histogram represents each of these buckets with a bar that tells us how many numbers from our list are in each bucket.
Counting the numbers in each bucket is not too hard if you use a list, some integer division, and the accumulator pattern.
Returning to the example of numbers between 0 and 100, consider the number 23, we know that should go in the 3rd bucket (or bucket number 2 counting from 0) for numbers between 20-29, and lucky for us 23 // 10 is 2. Try some other examples and convince yourself this works.
For every number we figure out what bucket it belongs to and then we add 1 to the value in that position of our list.
Calculating the buckets is the hard part of this project, the rest of the code you can easily steal from the bar chart part of this project. So, lets focus on that part first.
Given a list of numbers compute the counts for each bucket as represented by the bucket list. (get it!) Assume that the numbers can be in the range from 0 – 100. Do not cheat and count these manually. Tell yourself that test_numbers has ten thousand numbers on it.
Now repeat what you did before, but use the loan_amount list. This time it is a little more complicated because you will need to create your own bucket list, and the numbers are spread out over a much larger range that does not start at 0. You don’t want to waste any bins so you need to evenly divide the spread of the numbers in the loan_amount list. Note: This is a good problem for learning about boundary conditions.
Finally now put it all together and draw a histogram of the loan_amount data with 10 buckets.
As an added challenge, suppose you ask the user how many buckets they would like and then graph the data with as many buckets as the user asks for.
Post Project Questions
-
During this project I was primarily in my...
- 1. Comfort Zone
- 2. Learning Zone
- 3. Panic Zone
-
Completing this project took...
- 1. Very little time
- 2. A reasonable amount of time
- 3. More time than is reasonable
-
Based on my own interests and needs, the things taught in this project...
- 1. Don't seem worth learning
- 2. May be worth learning
- 3. Are definitely worth learning
-
For me to master the things taught in this project feels...
- 1. Definitely within reach
- 2. Within reach if I try my hardest
- 3. Out of reach no matter how hard I try