Breadth First Search¶
Say a computer is trying to find the best route from one location to another - it knows about a whole bunch of locations, and connections between the locations. Given this information, one strategy for finding a path from a particular location A to some other location Z is to start from A and explore every possible location you can get directly from A - all the places you can get to in exactly one “step”. Once you have done that, explore every location you can get to from those locations - all the places you could get to using two “steps” from location A.
The animation below visualizes this exact algorithm. The dots (vertices in the language used in computer science) represent locations and the lines between them (known as edges) represent possible “steps”. You can watch the computer “explore” all the paths of length 1, then all the paths of length 2, then all the paths of length 3, etc… until it discovers a path to get from the starting location in the lower-left corner to its destination in the upper right corner.
In the animation, every time an edge is explored that leads to a new location, it is turned red. To reach any location that has been explored, there will be a single path consisting of the red lines. When we explore an edge and discover that it leads to a location we have already discovered, it is left gray and never considered again.
Because the computer considers all the 1-step paths first, then 2-step, etc… we will never discover a new “shorter” route to a location we have already found. Thus, we can be confident that any time we discover a new path to a known location, it is not as good as the old path. In the picture below, say we discover that from location A we can jump to locations B, C and D in one step. Later we realize you can get from C to B in one step. There would not be any reason to use that path; why go from A to C then to B when we could just go from A to B?
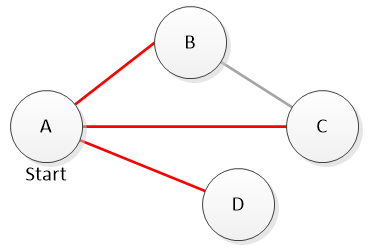
We will never need to use the edge between B and C. We can directly go to B or C from our starting location A.
By the same logic we can argue that as soon as the algorithm finds out destination, we can stop and be confident that we have found the most efficient path. Because the algorithm checks all possible paths of length n - 1 before checking any paths of length n, once we find a path with n steps to our final location we know that:
If there was a shorter path possible (something of n - 1) it would have already been found
Any paths we would discover if we kept looking would be at least as many steps if not more